개요
Fess 에서는 데이터베이스나 CSV 등의 데이터 소스를 크롤링 대상으로 지정할 수 있습니다. 여기서는 이를 위해 필요한 데이터 저장소 설정에 대해 설명합니다.
관리 방법
표시 방법
아래 그림의 데이터 저장소 설정 목록 페이지를 열려면 왼쪽 메뉴의 [크롤러 > 데이터 저장소]를 클릭합니다.
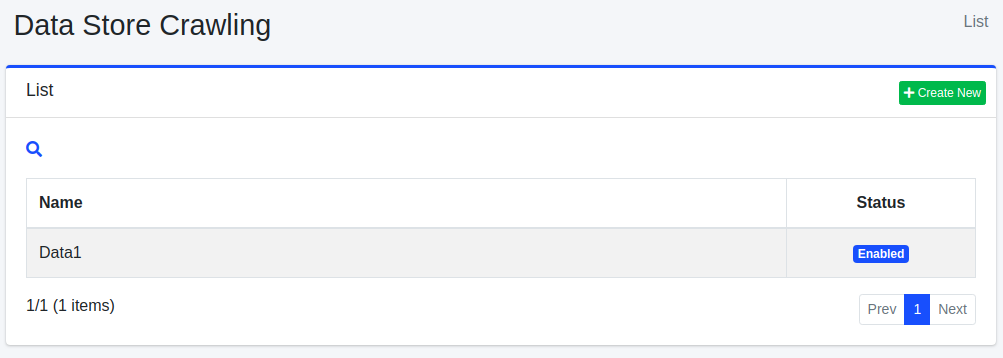
편집하려면 설정 이름을 클릭합니다.
설정 생성
데이터 저장소 설정 페이지를 열려면 신규 생성 버튼을 클릭합니다.
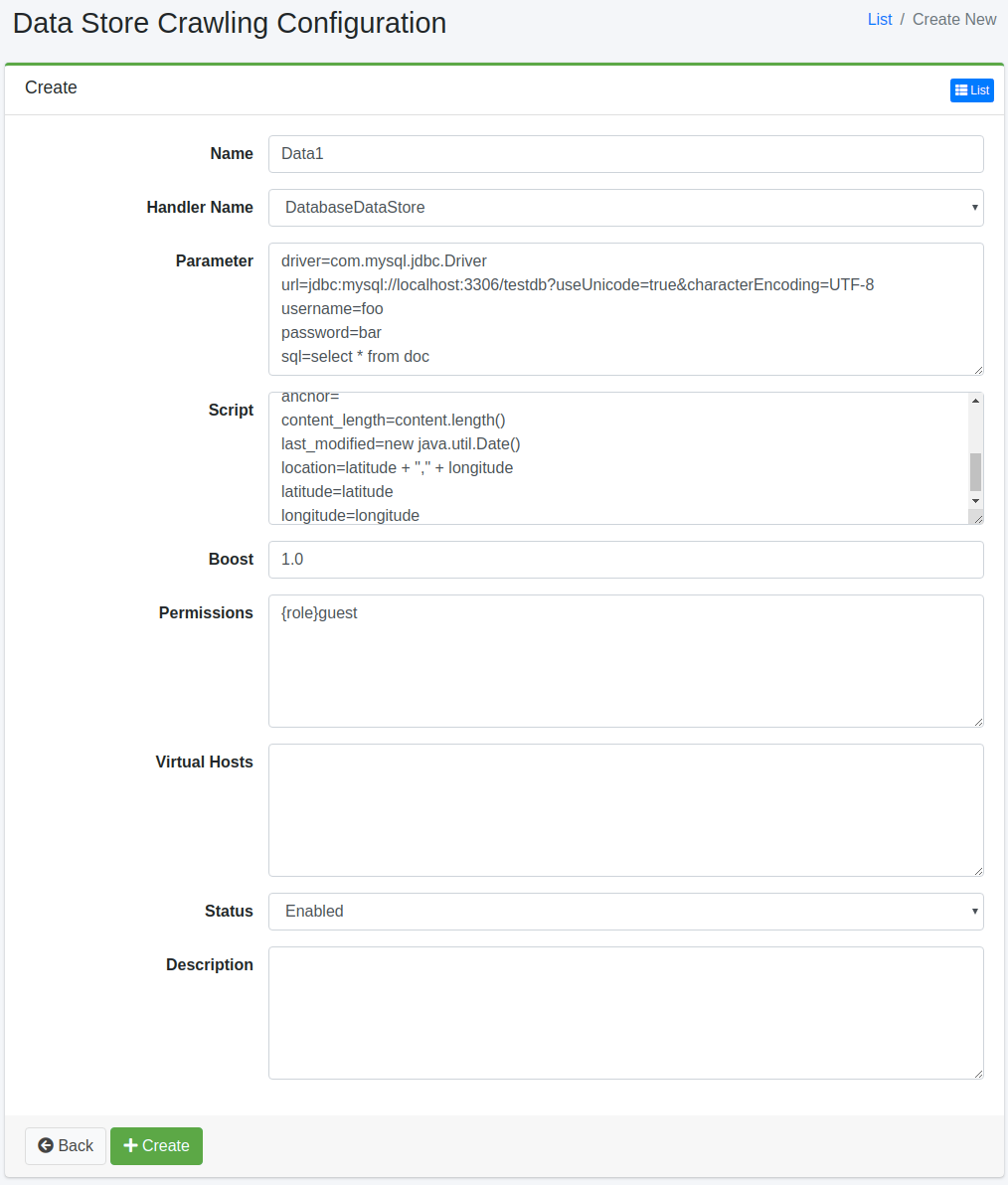
설정 항목
이름
크롤링 설정 이름을 지정합니다.
핸들러 이름
데이터 저장소를 처리하는 핸들러 이름입니다.
DatabaseDataStore: 데이터베이스를 크롤링합니다
CsvDataStore: CSV/TSV 파일을 대상으로 크롤링합니다
CsvListDataStore: 인덱싱 대상 파일 경로를 기술한 CSV 파일을 크롤링합니다
매개변수
데이터 저장소에 관한 매개변수를 지정합니다.
스크립트
데이터 저장소에서 가져온 값을 어떤 필드에 설정할지 등을 지정합니다. 표현식은 Groovy로 작성할 수 있습니다.
부스트 값
이 설정으로 크롤링할 때 문서의 부스트 값을 지정합니다.
권한
이 설정의 권한을 지정합니다. 권한 지정 방법은 예를 들어, developer 그룹에 속한 사용자에게 검색 결과를 표시하려면 {group}developer로 지정합니다. 사용자 단위 지정은 {user}사용자명, 역할 단위 지정은 {role}역할명, 그룹 단위 지정은 {group}그룹명으로 지정합니다.
가상 호스트
가상 호스트의 호스트명을 지정합니다. 자세한 내용은 설정 가이드의 가상 호스트 를 참조하십시오.
상태
이 크롤링 설정을 사용할지 여부를 지정합니다.
설명
설명을 입력할 수 있습니다.
설정 삭제
목록 페이지의 설정 이름을 클릭하고 삭제 버튼을 클릭하면 확인 화면이 표시됩니다. 삭제 버튼을 누르면 설정이 삭제됩니다.
예
DatabaseDataStore
데이터베이스 크롤링에 대해 설명합니다.
예를 들어, 다음과 같은 테이블이 MySQL의 testdb 라는 데이터베이스에 있고, 사용자 이름 hoge, 비밀번호 fuga 로 접속할 수 있다고 가정하고 설명합니다.
여기서는 다음과 같은 데이터를 입력해 둡니다.
매개변수
매개변수 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키에 대한 설명은 다음과 같습니다.
| driver | 드라이버 클래스 이름 |
| url | URL |
| username | DB에 접속할 때의 사용자 이름 |
| password | DB에 접속할 때의 비밀번호 |
| sql | 크롤링 대상을 얻기 위한 SQL 문 |
표: DB용 설정 매개변수 예
스크립트
스크립트 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키에 대한 설명은 다음과 같습니다.
값 측은 Groovy로 작성합니다. 문자열은 큰따옴표로 묶으십시오. 데이터베이스의 열 이름으로 액세스하면 그 값이 됩니다.
| url | URL(사용 중인 환경에 맞춰 데이터에 액세스 가능한 URL을 설정하십시오) |
| host | 호스트 이름 |
| site | 사이트 경로 |
| title | 제목 |
| content | 문서의 콘텐츠(인덱스 대상 문자열) |
| cache | 문서의 캐시(인덱스 대상이 아님) |
| digest | 검색 결과에 표시되는 다이제스트 부분 |
| anchor | 문서에 포함된 링크(일반적으로 지정할 필요가 없음) |
| content_length | 문서의 길이 |
| last_modified | 문서의 최종 수정 날짜 |
표: 스크립트 설정 내용
드라이버
데이터베이스에 접속할 때는 드라이버가 필요합니다. app/WEB-INF/lib 에 jar 파일을 배치하십시오.
CsvDataStore
CSV 파일을 대상으로 한 크롤링에 대해 설명합니다.
예를 들어, /home/taro/csv 디렉터리에 test.csv 파일을 다음과 같은 내용으로 생성해 둡니다. 파일 인코딩은 Shift_JIS로 설정합니다.
매개변수
매개변수 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키에 대한 설명은 다음과 같습니다.
| directories | CSV 파일이 포함된 디렉터리 (.csv 또는 .tsv) |
| files | CSV 파일 (직접 지정하는 경우) |
| fileEncoding | CSV 파일의 인코딩 |
| separatorCharacter | 구분 문자 |
표: CSV 파일용 설정 매개변수 예
스크립트
스크립트 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키는 데이터베이스 크롤링의 경우와 동일합니다. CSV 파일 내의 데이터는 cell[숫자]로 보유하고 있습니다(숫자는 1부터 시작). CSV 파일의 셀에 데이터가 존재하지 않는 경우 null이 될 수 있습니다.
EsDataStore
데이터 가져오기 대상이 elasticsearch가 되지만, 기본적인 사용 방법은 CsvDataStore와 동일합니다.
매개변수
매개변수 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키에 대한 설명은 다음과 같습니다.
| settings.* | elasticsearch의 Settings 정보 |
| hosts | 접속할 elasticsearch |
| index | 인덱스 이름 |
| type | 타입 이름 |
| query | 가져올 조건의 쿼리 |
표: elasticsearch용 설정 매개변수 예
스크립트
스크립트 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키는 데이터베이스 크롤링의 경우와 동일합니다. source.*를 통해 값을 가져와서 설정할 수 있습니다.
CsvListDataStore
대량의 파일을 크롤링할 때 사용합니다. 업데이트된 파일의 경로를 기록한 CSV 파일을 배치하고, 지정된 경로만 크롤링하여 크롤링 실행 시간을 단축할 수 있습니다.
경로를 기술할 때의 형식은 다음과 같습니다.
액션에는 다음 중 하나를 지정합니다.
create: 파일이 생성됨
modify: 파일이 업데이트됨
delete: 파일이 삭제됨
예를 들어, /home/taro/csv 디렉터리에 test.csv 파일을 다음과 같은 내용으로 생성해 둡니다. 파일 인코딩은 Shift_JIS로 설정합니다.
경로는 파일 크롤링에서 크롤링 대상 경로를 지정할 때와 동일한 표기법으로 경로를 기술합니다. 다음과 같이 “file:/[경로]” 또는 “smb://[경로]”로 지정합니다.
매개변수
매개변수 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키에 대한 설명은 다음과 같습니다.
| directories | CSV 파일이 포함된 디렉터리 (.csv 또는 .tsv) |
| fileEncoding | CSV 파일의 인코딩 |
| separatorCharacter | 구분 문자 |
표: CSV 파일용 설정 매개변수 예
스크립트
스크립트 설정 예는 다음과 같습니다.
매개변수는 “키=값” 형식입니다. 키는 데이터베이스 크롤링의 경우와 동일합니다.
크롤링 대상에 인증이 필요한 경우 다음도 설정해야 합니다.