Übersicht
Mit Fess können Sie Datenquellen wie Datenbanken oder CSV als Crawl-Ziele festlegen. Hier wird die erforderliche Datenspeicherkonfiguration dafür erläutert.
Verwaltung
Anzeige
Um die Übersichtsseite für die Datenspeicherkonfiguration zu öffnen, klicken Sie im linken Menü auf [Crawler > Datenspeicher].

Klicken Sie auf den Konfigurationsnamen, um ihn zu bearbeiten.
Konfiguration erstellen
Um die Datenspeicherkonfigurationsseite zu öffnen, klicken Sie auf die Schaltfläche „Neu erstellen“.
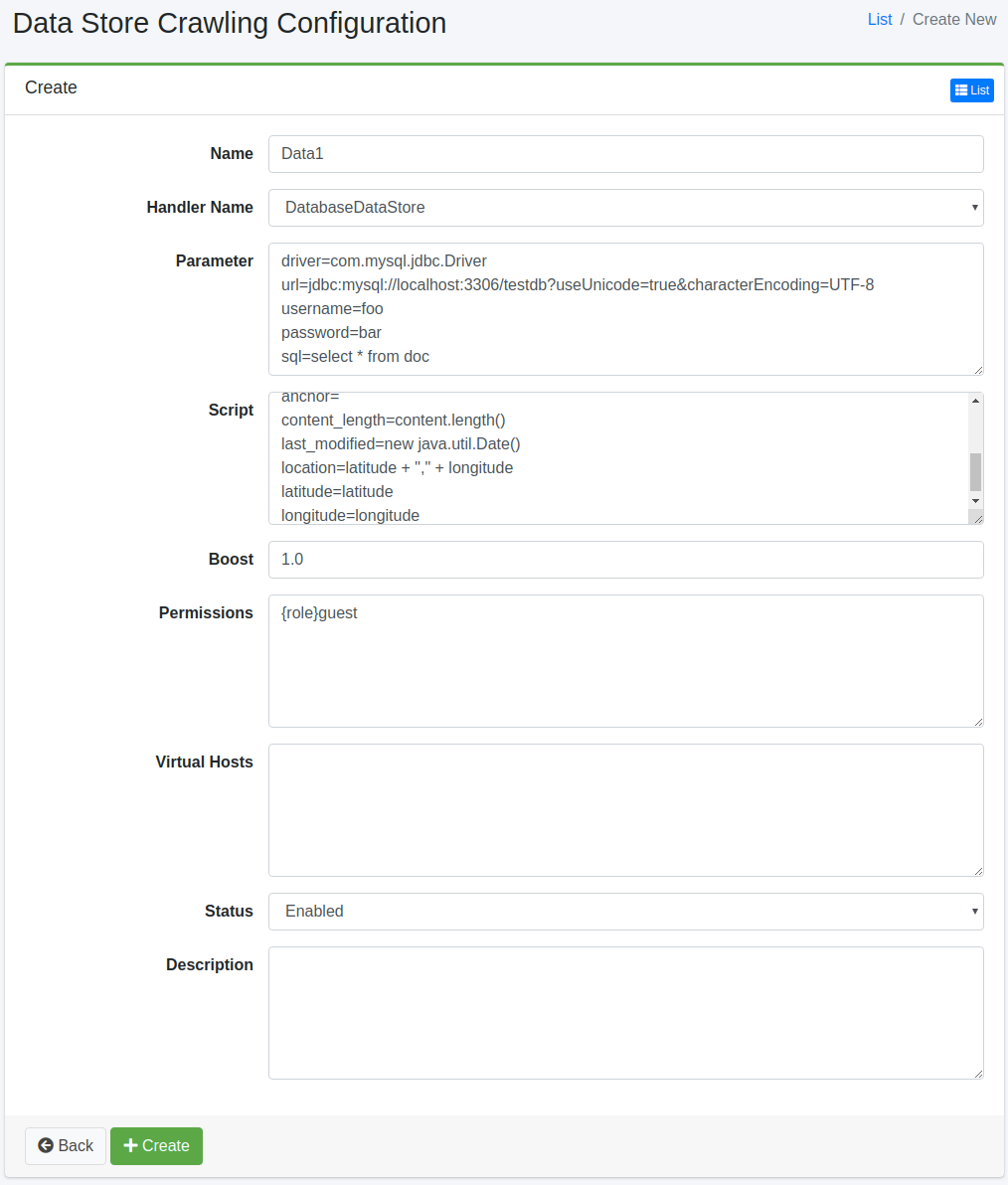
Konfigurationsparameter
Name
Geben Sie den Namen der Crawl-Konfiguration an.
Handler-Name
Der Handler-Name zur Verarbeitung des Datenspeichers.
DatabaseDataStore: Crawlt eine Datenbank
CsvDataStore: Crawlt CSV/TSV-Dateien
CsvListDataStore: Crawlt eine CSV-Datei, die Dateipfade zu indizierenden Dateien beschreibt
Parameter
Geben Sie Parameter für den Datenspeicher an.
Skript
Geben Sie an, in welchen Feldern die vom Datenspeicher abgerufenen Werte festgelegt werden sollen. Ausdrücke können in Groovy geschrieben werden.
Boost-Wert
Geben Sie den Boost-Wert für Dokumente an, die mit dieser Konfiguration gecrawlt werden.
Berechtigung
Geben Sie die Berechtigung für diese Konfiguration an. Um beispielsweise Suchergebnisse für Benutzer anzuzeigen, die zur Gruppe „developer“ gehören, geben Sie {group}developer an. Für Benutzerebene geben Sie {user}Benutzername an, für Rollenebene {role}Rollenname und für Gruppenebene {group}Gruppenname.
Virtueller Host
Geben Sie den Hostnamen des virtuellen Hosts an. Weitere Details finden Sie unter Virtueller Host im Konfigurationshandbuch.
Status
Geben Sie an, ob diese Crawl-Konfiguration verwendet werden soll.
Beschreibung
Sie können eine Beschreibung eingeben.
Konfiguration löschen
Klicken Sie auf den Konfigurationsnamen auf der Übersichtsseite und dann auf die Schaltfläche „Löschen“. Es wird ein Bestätigungsbildschirm angezeigt. Klicken Sie auf die Schaltfläche „Löschen“, um die Konfiguration zu löschen.
Beispiele
DatabaseDataStore
Datenbank-Crawling wird erklärt.
Als Beispiel wird eine Tabelle in der MySQL-Datenbank testdb wie folgt angenommen, auf die mit Benutzername hoge und Passwort fuga zugegriffen werden kann.
Hier fügen wir folgende Daten ein:
Parameter
Ein Beispiel für die Parameterkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüsselerklärungen sind wie folgt:
| driver | Treiberklassenname |
| url | URL |
| username | Benutzername für die Datenbankverbindung |
| password | Passwort für die Datenbankverbindung |
| sql | SQL-Anweisung zum Abrufen von Crawl-Zielen |
Tabelle: Beispiel für DB-Konfigurationsparameter
Skript
Ein Beispiel für die Skriptkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüsselerklärungen sind wie folgt:
Die Werte werden in Groovy geschrieben. Schließen Sie Zeichenketten in doppelte Anführungszeichen ein. Durch Zugriff auf den Datenbank-Spaltennamen wird der entsprechende Wert abgerufen.
| url | URL (Passen Sie sie an Ihre Umgebung an, um eine URL zu konfigurieren, über die auf die Daten zugegriffen werden kann) |
| host | Hostname |
| site | Site-Pfad |
| title | Titel |
| content | Dokumentinhalt (zu indizierender Text) |
| cache | Dokument-Cache (nicht zu indizieren) |
| digest | In Suchergebnissen angezeigter Digest-Teil |
| anchor | Im Dokument enthaltene Links (normalerweise nicht erforderlich) |
| content_length | Dokumentlänge |
| last_modified | Letztes Änderungsdatum des Dokuments |
Tabelle: Skriptkonfigurationsinhalt
Treiber
Zum Verbinden mit der Datenbank ist ein Treiber erforderlich. Platzieren Sie die JAR-Datei in app/WEB-INF/lib.
CsvDataStore
CSV-Datei-Crawling wird erklärt.
Erstellen Sie beispielsweise eine test.csv-Datei im Verzeichnis /home/taro/csv mit folgendem Inhalt. Die Dateikodierung sollte Shift_JIS sein.
Parameter
Ein Beispiel für die Parameterkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüsselerklärungen sind wie folgt:
| directories | Verzeichnis mit CSV-Dateien (.csv oder .tsv) |
| files | CSV-Dateien (bei direkter Angabe) |
| fileEncoding | Kodierung der CSV-Datei |
| separatorCharacter | Trennzeichen |
Tabelle: Beispiel für CSV-Datei-Konfigurationsparameter
Skript
Ein Beispiel für die Skriptkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüssel sind dieselben wie beim Datenbank-Crawling. Daten in CSV-Dateien werden in cell[Nummer] gespeichert (Nummern beginnen bei 1). Wenn keine Daten in einer CSV-Zelle vorhanden sind, kann der Wert null sein.
EsDataStore
Die Datenquelle ist Elasticsearch, aber die grundlegende Verwendung ist dieselbe wie bei CsvDataStore.
Parameter
Ein Beispiel für die Parameterkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüsselerklärungen sind wie folgt:
| settings.* | Elasticsearch-Einstellungsinformationen |
| hosts | Elasticsearch-Verbindungsziel |
| index | Indexname |
| type | Typname |
| query | Abfrage für Abrufbedingungen |
Tabelle: Beispiel für Elasticsearch-Konfigurationsparameter
Skript
Ein Beispiel für die Skriptkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüssel sind dieselben wie beim Datenbank-Crawling. Sie können Werte mit source.* abrufen und festlegen.
CsvListDataStore
Wird zum Crawlen großer Dateimengen verwendet. Durch Platzieren einer CSV-Datei mit Pfaden zu aktualisierten Dateien und Crawlen nur der angegebenen Pfade kann die Crawl-Ausführungszeit verkürzt werden.
Das Format zum Beschreiben von Pfaden ist wie folgt:
Geben Sie eine der folgenden Aktionen an:
create: Datei wurde erstellt
modify: Datei wurde aktualisiert
delete: Datei wurde gelöscht
Erstellen Sie beispielsweise eine test.csv-Datei im Verzeichnis /home/taro/csv mit folgendem Inhalt. Die Dateikodierung sollte Shift_JIS sein.
Pfade werden in derselben Notation wie bei der Angabe von Crawl-Zielpfaden beim Datei-Crawling beschrieben. Geben Sie wie folgt „file:/[Pfad]“ oder „smb://[Pfad]“ an:
Parameter
Ein Beispiel für die Parameterkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüsselerklärungen sind wie folgt:
| directories | Verzeichnis mit CSV-Dateien (.csv oder .tsv) |
| fileEncoding | Kodierung der CSV-Datei |
| separatorCharacter | Trennzeichen |
Tabelle: Beispiel für CSV-Datei-Konfigurationsparameter
Skript
Ein Beispiel für die Skriptkonfiguration ist wie folgt:
Parameter haben das Format „Schlüssel=Wert“. Die Schlüssel sind dieselben wie beim Datenbank-Crawling.
Wenn für das Crawl-Ziel eine Authentifizierung erforderlich ist, müssen auch folgende Einstellungen konfiguriert werden: