Overview
Web Crawling Configuaration page manages configurations for Web crawling.
Management Operations
Display Configurations
Select Crawler > Web in the left menu to display a list page of Web Crawling Configuration, as below.
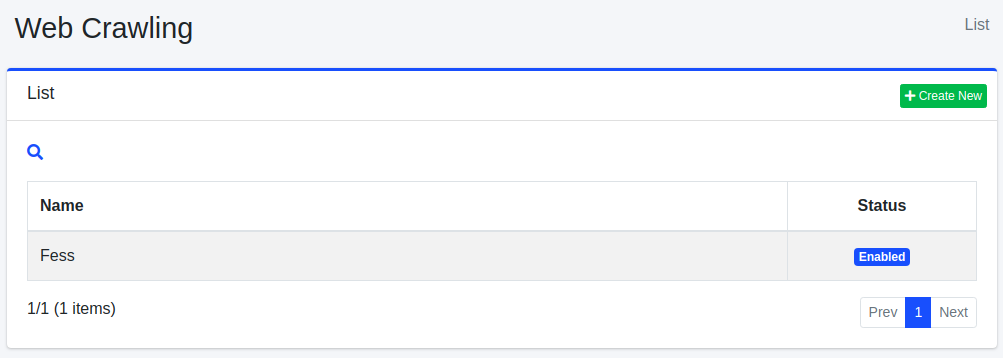
Click a configuration name if you want to edit it.
Create Configuration
Click Create New button to display a form page for Web crawling configuration.
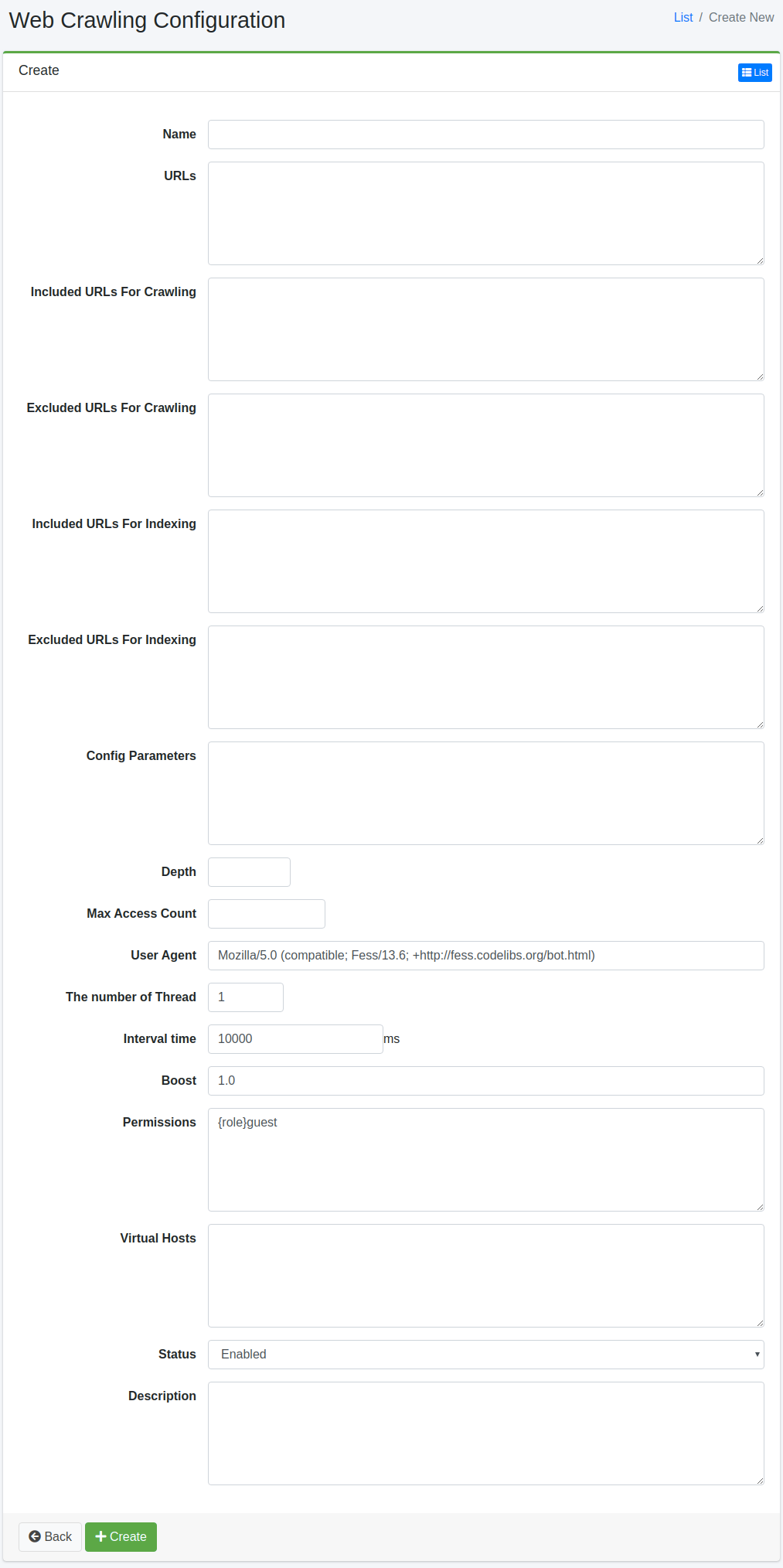
Configurations
Name
Configuration name.
URLs
This URLs are locations to start crawling.
Included URLs For Crawling
This regular expression(Java Format) is allowed url patterns for Fess crawler.
Excluded URLs For Crawling
This regular expression(Java Format) is rejected url patterns for Fess crawler.
Included URLs For Indexing
This regular expression(Java Format) is allowed url patterns for Fess indexer.
Excluded URLs For Indexing
This regular expression(Java Format) is rejected url patterns for Fess indexer.
Config parameters
You can specify the crawl configuration information.
Depth
The number of linked urls.
Max Access Count
The number of indexed urls.
User Agent
Name of Fess crawler.
The number of Thread
The number of crawler threads for this configuration.
Interval time
Interval time to crawl urls for each thread.
Boost
Boost value is a weight for indexed documents of this configuration.
Permissions
Permissions for this configuration. This format is “{user/group/role}name”. For example, to display search results on users who belong to developer group, the permission is {group}developer.
Virtual Hosts
Virtual Host keys for this configuration. e.g. fess (if setting Host:fess.codelibs.org=fess in General)
Labels
Labels for this configuration.
Status
If enabled, the scheduled job of Default Crawler includes this configuration.
Description
Comments for this configuration.
Delete Configuration
Click a configuration on a list page, and click Delete button to display a confirmation dialog. Click Delete button to delete the configuration.
Example
Crawling Fess Site
If you want to create Web crawling configuration to crawl pages under https://fess.codelibs.org/, parameters are:
| Name | Value |
|---|---|
| Name | Fess |
| URLs | https://fess.codelibs.org/ |
| Included URLs For Crawling | https://fess.codelibs.org/.* |
For other parameters, use a default value.
Crawling Protected Site
Fess supports BASIC/DIGEST/NTLM/FORM authentication. For the authentication information, you can configure it on Web Authentication page.
Redmine
To crawl Redmine pages (ex. https://<server>/) with password protection, create a setting on Web Config page as below:
| Name | Value |
|---|---|
| Name | Redmine |
| URLs | https://<server>/my/page |
| Included URLs For Crawling | https://<server>/.* |
| Config Parameters | client.robotsTxtEnabled=false (Optional) |
and then create the authentication setting on Web Auth page:
| Name | Value |
|---|---|
| Scheme | Form |
| Username | (Account for crawling) |
| Password | (Password for the account) |
| Parameters | encoding=UTF-8 token_method=GET token_url=https://<server>/login token_pattern=name=”authenticity_token”[^>]+value=”([^”]+)” token_name=authenticity_token login_method=POST login_url=https://<server>/login login_parameters=username=${username}&password=${password} |
| Web Config | Redmine |
XWiki
To crawl XWiki pages (ex. https://<server>/xwiki/), Web Crawling setting is:
| Name | Value |
|---|---|
| Name | XWiki |
| URLs | https://<server>/xwiki/bin/view/Main/ |
| Included URLs For Crawling | https://<server>/.* |
| Config Parameters | client.robotsTxtEnabled=false (Optional) |
and the authentication setting is:
| Name | Value |
|---|---|
| Scheme | Form |
| Username | (Account for crawling) |
| Password | (Password for the account) |
| Parameters | encoding=UTF-8 token_method=GET token_url=http://<server>/xwiki/bin/login/XWiki/XWikiLogin token_pattern=name=”form_token” +value=”([^”]+)” token_name=form_token login_method=POST login_url=http://<server>/xwiki/bin/loginsubmit/XWiki/XWikiLogin login_parameters=j_username=${username}&j_password=${password} |
| Web Config | XWiki |