This page is generated by Machine Translation from Japanese.
Overview
Describes the settings for crawl here, using file system.
Recommends that if you want to index document number 100000 over in Fess crawl settings for one to several tens of thousands of these. One crawl setting a target number 100000 from the indexed performance degrades.
How to set up
How to display
In Administrator account after logging in, click menu file.
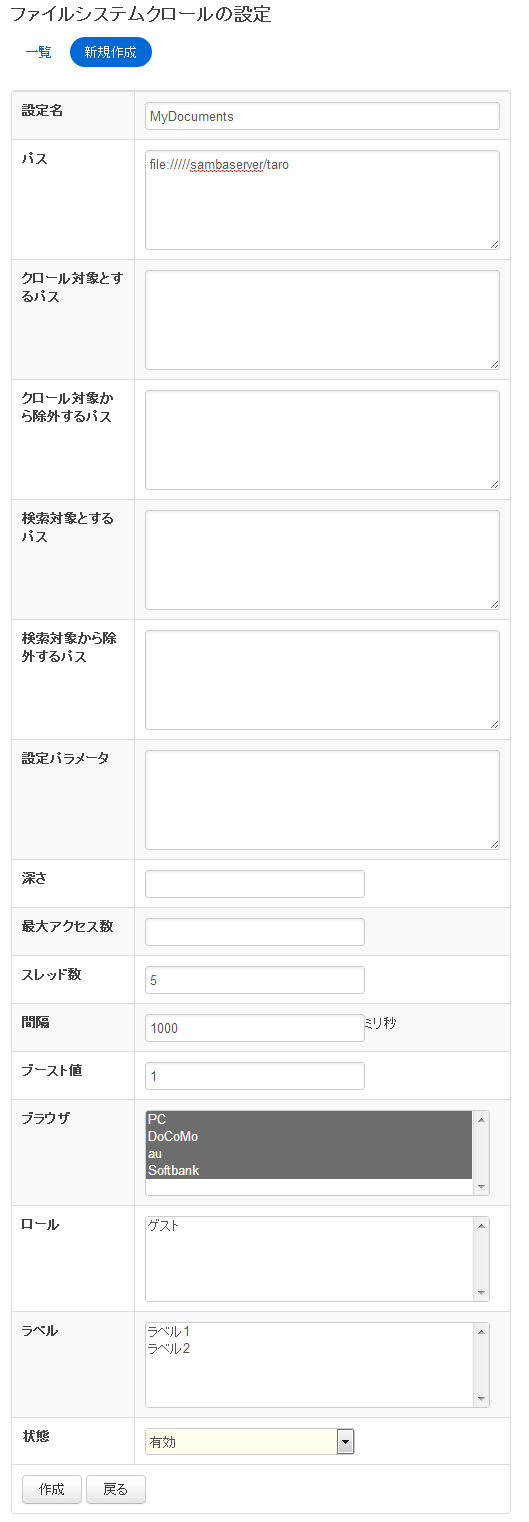
Setting item
Setting name
Is the name that appears on the list page.
Specifying a path
You can specify multiple paths. file: or smb: in the specify starting. For example,
The so determines. Patrolling below the specified directory.
So there is need to write URI if the Windows environment path that c:\Documents\taro in file/c: /Documents/taro and specify.
Windows shared folder, for example, if you want to crawl to host1 share folder crawl settings for smb: (last / to) the //host1/share/. If authentication is in the shared folder on the file system authentication screen set authentication information.
Path filtering
By specifying regular expressions you can exclude the crawl and search for given path pattern.
| Path to crawl | Crawl the path for the specified regular expression. |
| The path to exclude from being crawled | The path for the specified regular expression does not crawl. The path you want to crawl, even WINS here. |
| Path to be searched | The path for the specified regular expression search. Even if specified path to find excluded and WINS here. |
| Path to exclude from searches | Not search the path for the specified regular expression. Unable to search all links since they exclude from being crawled and crawled when the search and not just some. |
Table: IP rings contents list
For example, the path to target if you don’t crawl less than/home /
Also the path to exclude if extension of png want to exclude from
It specifies. It is possible to specify multiple line breaks in.
How to specify the URI handling java.io.File: Looks like:
Setting parameters
You can specify the crawl configuration information.
Depth
Specify the depth of a directory hierarchy.
Maximum access
You can specify the number of documents to retrieve crawl.
Number of threads
Specifies the number of threads you want to crawl. Value of 5 in 5 threads crawling the website at the same time.
Interval
Is the time interval to crawl documents. 5000 when one thread is 5 seconds at intervals Gets the document.
Number of threads, 5 pieces, will be to go to and get the 5 documents per second between when 1000 millisecond interval,.
Boost value
You can search URL in this crawl setting to weight. Available in the search results on other than you want to. The standard is 1. Priority higher values, will be displayed at the top of the search results. If you want to see results other than absolutely in favor, including 10,000 sufficiently large value.
Values that can be specified is an integer greater than 0. This value is used as the boost value when adding documents to Solr.
Browser type
Register the browser type was selected as the crawled documents. Even if you select only the PC search on your mobile device not appear in results. If you want to see only specific mobile devices also available.
Roll
You can control only when a particular user role can appear in search results. You must roll a set before you. For example, available by the user in the system requires a login, such as portal servers, search results out if you want.
Label
You can label with search results. Search on each label, such as enable, in the search screen, specify the label.
State
Crawl crawl time, is set to enable. If you want to avoid crawling temporarily available.