Overview
This section explains the settings for the job scheduler.
Management Operations
Display Configurations
To view the list of job scheduler settings shown in the following figure, click on [System > Scheduler] in the left menu.
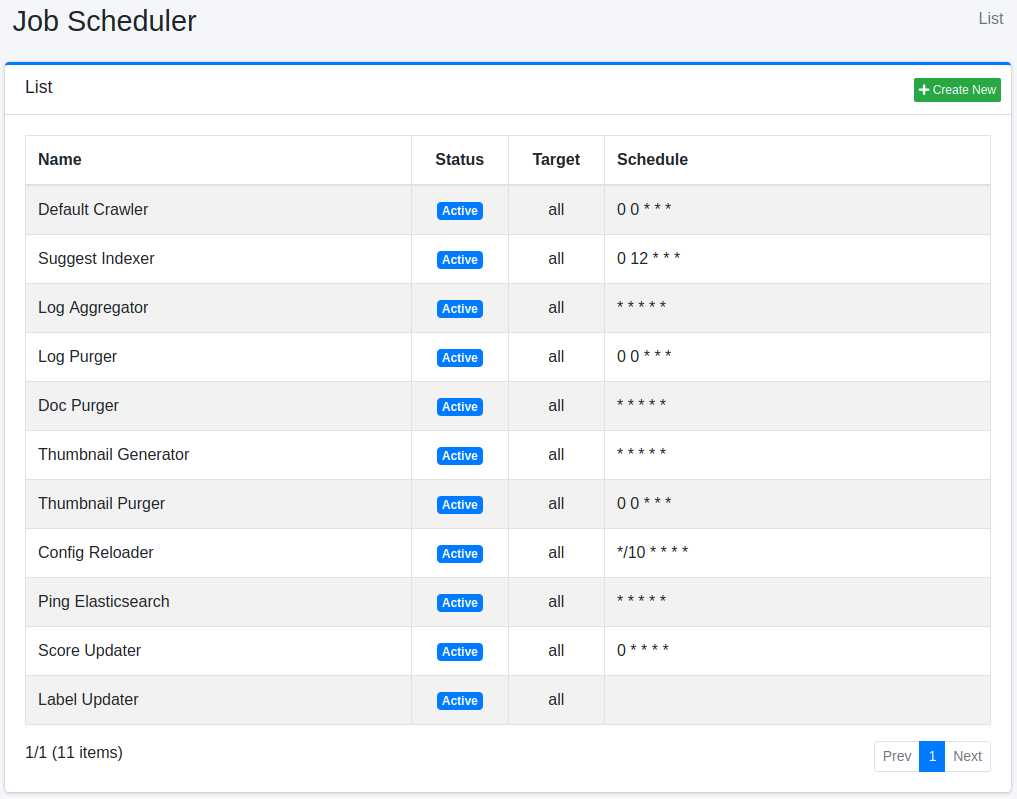
To edit the settings, click on the name of the setting.
Create Configuration
To create a new setting, click on the “New” button on the scheduler settings page.
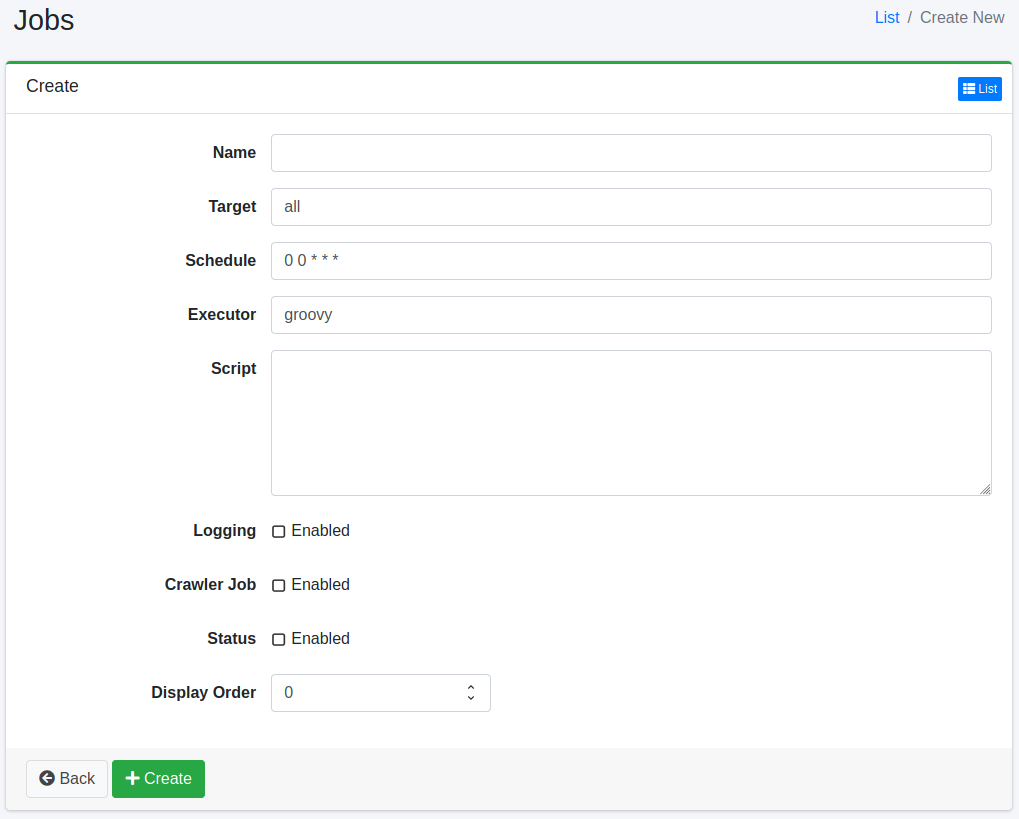
Configurations
Name
The name displayed in the list.
Target
The target is used as an identifier for whether the job should be executed directly by a batch command or not. Specify “all” if crawling is not performed using a command execution.
Schedule
Set the schedule here. The jobs written in the script will be executed according to the schedule set here.
The format is in CRON format and is written in the form of “minute hour day month day of the week”. For example, “0 12 * * 3” runs the job every Wednesday at 12:00 PM.
Executor
Specify the script execution environment. Currently, only “groovy” is supported.
Script
Write the content of the job execution in the language specified in the execution method.
For example, if you want to execute only three crawl settings as crawl jobs (assuming the ID of web crawl settings are 1 and 2, and the ID of file system crawl settings is 1), write it as follows:
` return container.getComponent("crawlJob").logLevel("info").webConfigIds(["1", "2"] as String[]).fileConfigIds(["1"] as String[]).dataConfigIds([] as String[]).execute(executor); `
Logging
If enabled, it will be recorded in the job log.
Crawler Job
If enabled, it will be treated as a crawler job.
Status
Specify the enabled/disabled state of the job. If disabled, the job will not be executed.
Display Order
Specify the display order in the job list.
Delete Configuration
Click the setting name on the list page and click the delete button to display the confirmation screen. Clicking the delete button will delete the setting.
Manual Crawling Method
Click “Default Crawler” in the “Scheduler” and click the “Start Now” button. To stop crawling, click “Default Crawler” and then click the “Stop” button.