Introduction
Les documents à gérer augmentent jour après jour, et il est nécessaire de les gérer efficacement pour exploiter les connaissances. Plus le nombre de documents à gérer augmente, plus il devient difficile de trouver ceux contenant des informations spécifiques. Une solution à ce problème consiste à introduire un serveur de recherche en texte intégral capable de rechercher dans une grande quantité d’informations.
Fess est un serveur de recherche en texte intégral open source basé sur Java, facile à déployer. Le moteur de recherche de Fess utilise Elasticsearch. Elasticsearch est un moteur de recherche haute performance, évolutif et flexible, basé sur Lucene. D’autre part, si vous souhaitez construire un système de recherche en texte intégral avec Elasticsearch, vous devez implémenter vous-même diverses fonctionnalités telles que la partie crawler. Fess utilise Fess Crawler pour la partie crawler, permettant de collecter différents types de documents sur le web et les systèmes de fichiers pour les indexer.
Cet article présente la construction d’un serveur de recherche avec Fess.
Public visé
Personnes souhaitant construire un système de recherche d’entreprise/système de recherche
Personnes souhaitant ajouter une fonctionnalité de recherche à un système existant
Personnes souhaitant créer un environnement de recherche interne pour exploiter les connaissances
Personnes intéressées par les logiciels de recherche tels que Lucene ou Elasticsearch
Environnement requis
Le contenu de cet article a été vérifié dans l’environnement suivant.
Ubuntu 22.04
OpenJDK 21
Qu’est-ce que Fess
Fess est un système de recherche en texte intégral open source ciblant le web et les systèmes de fichiers. Il est fourni sous licence Apache depuis le site Fesspar le projet CodeLibs sur GitHub.
Caractéristiques de Fess
Système de recherche basé sur Java
Fess est construit en utilisant divers produits open source.
La distribution est fournie sous forme d’application exécutable. Fess fournit une interface de recherche et une interface d’administration. Fess adopte LastaFlute comme framework web. Par conséquent, si vous devez personnaliser l’interface, vous pouvez facilement le faire en modifiant les JSP. De plus, les données de configuration et les données d’exploration sont stockées dans OpenSearch, et l’accès à ces données se fait en utilisant l’O/R mapper DBFlute.
Fess étant construit comme un système basé sur Java, il peut être exécuté sur toutes les plateformes prenant en charge Java. Il dispose également d’une interface utilisateur web facile à utiliser pour configurer les différents paramètres.
Utilisation d’OpenSearch comme moteur de recherche
OpenSearch est un moteur de recherche et d’analyse open source fourni par AWS, basé sur Lucene. Ses caractéristiques incluent la prise en charge de la recherche en temps réel, de la mise en évidence des résultats de recherche et des fonctionnalités d’agrégation. De plus, le nombre de documents pouvant être indexés peut atteindre des centaines de millions en fonction de la configuration du serveur OpenSearch, ce qui en fait un serveur de recherche évolutif pour les sites à grande échelle. Il existe de nombreux cas d’utilisation au Japon et c’est l’un des moteurs de recherche qui attire l’attention.
Fess adopte OpenSearch comme moteur de recherche. La version Docker de Fess est distribuée avec OpenSearch intégré, mais il est également possible de séparer le serveur Fess et OpenSearch. De plus, Fess et OpenSearch peuvent chacun être configurés en redondance, ce qui permet de tirer parti de leur haute extensibilité.
Utilisation de Fess Crawler comme moteur d’exploration
Fess Crawler est un framework de crawler fourni par le projet CodeLibs. Fess Crawler peut parcourir et collecter des documents sur le web et les systèmes de fichiers. La collecte de documents peut également traiter efficacement plusieurs documents simultanément en multi-threading. Les documents pris en charge incluent bien sûr le HTML, mais aussi les fichiers MS Office tels que Word et Excel, les fichiers d’archive comme zip, et même les fichiers image et audio (pour les fichiers image et audio, les méta-informations sont extraites).
Fess utilise Fess Crawler pour parcourir les documents sur le web et les systèmes de fichiers et collecter les informations textuelles. Les formats de fichiers pris en charge sont ceux que Fess Crawler peut traiter. Les paramètres d’exécution de l’exploration par Fess Crawler peuvent être configurés depuis l’interface d’administration de Fess.
Installation et démarrage
Cette section explique les étapes pour démarrer Fess et effectuer une recherche. Bien que l’explication suppose une exécution sur Ubuntu 22.04, l’installation et le démarrage peuvent être effectués de manière similaire sur macOS et Windows.
Téléchargement et installation
Téléchargez le dernier package depuis https://github.com/codelibs/fess/releases. Au moment de la rédaction de cet article (2025/11), la dernière version est 15.3.0. Après le téléchargement, décompressez dans un répertoire de votre choix.
Téléchargement de Fess 
Téléchargez depuis la page de téléchargement d’OpenSearch. La page de téléchargement de Fess indique la version d’OpenSearch correspondant à chaque version, veuillez donc vérifier la version avant de télécharger. La version correspondant à Fess 15.3.0 est 3.3.0, téléchargez donc cette version. Après le téléchargement, décompressez dans un répertoire de votre choix.
Configuration
Avant de démarrer, configurez la connexion au cluster OpenSearch pour Fess. Pour les méthodes de configuration des packages ZIP/TAR.GZ, veuillez consulter la Méthode d’installationsur la page d’installation. Si vous utilisez des packages RPM/DEB, veuillez également consulter la même page d’installation.
Démarrage
Le démarrage est simple. Exécutez les commandes suivantes dans les répertoires décompressés opensearch-<version> et fess-<version>. Démarrez dans l’ordre OpenSearch → Fess.
Démarrage d’OpenSearch
Démarrage de Fess
Accédez à http://localhost:8080/ avec un navigateur. Si l’écran suivant s’affiche, c’est que le démarrage a réussi.
Écran d’accueil de recherche 
Arrêt
Pour arrêter le serveur Fess, arrêtez (kill) le processus Fess. Lors de l’arrêt, arrêtez dans l’ordre Fess → OpenSearch.
Structure des répertoires
La structure des répertoires est la suivante.
Structure des répertoires de Fess
Fess est construit sur la base de TomcatBoot fourni par LastaFlute. Les fichiers de l’application Fess sont placés sous le répertoire app. Bien qu’ils puissent également être modifiés depuis l’interface d’administration, les JSP de l’écran de recherche sont stockés sous app/WEB-INF/view. De plus, les fichiers js, css et images directement sous le répertoire app sont les fichiers utilisés par l’écran de recherche.
Structure des répertoires d’OpenSearch
Les données d’index sont stockées dans le répertoire data.
De la création d’index à la recherche
Immédiatement après le démarrage, aucun index n’a été créé pour la recherche, donc même en effectuant une recherche, aucun résultat ne sera retourné. Il faut donc d’abord créer un index. Nous allons expliquer ici comment créer un index pour https://fess.codelibs.org/ja/ et effectuer une recherche.
Connexion à la page d’administration
Tout d’abord, accédez à la page d’administration http://localhost:8080/admin et connectez-vous. Par défaut, le nom d’utilisateur et le mot de passe sont tous deux admin.
Connexion à la page d’administration 
Enregistrement des cibles d’exploration
Ensuite, enregistrez les cibles d’exploration. Comme nous ciblons les pages web cette fois, sélectionnez [Web] sur le côté gauche de la page d’administration. Dans l’état initial, rien n’est enregistré, sélectionnez donc [Nouveau].
Sélection de [Nouveau] 
Pour la configuration de l’exploration web, cette fois nous allons explorer les pages sous https://fess.codelibs.org/ja/ avec un intervalle de 10 secondes sur 2 threads (environ 2 pages toutes les 10 secondes), pour indexer environ 100 pages. Les paramètres de configuration sont : URL : https://fess.codelibs.org/ja/, URL à explorer : https://fess.codelibs.org/ja/.*, Nombre maximum d’accès : 100, Nombre de threads : 2, Intervalle : 10000 millisecondes, et les autres paramètres par défaut.
Configuration de l’exploration web 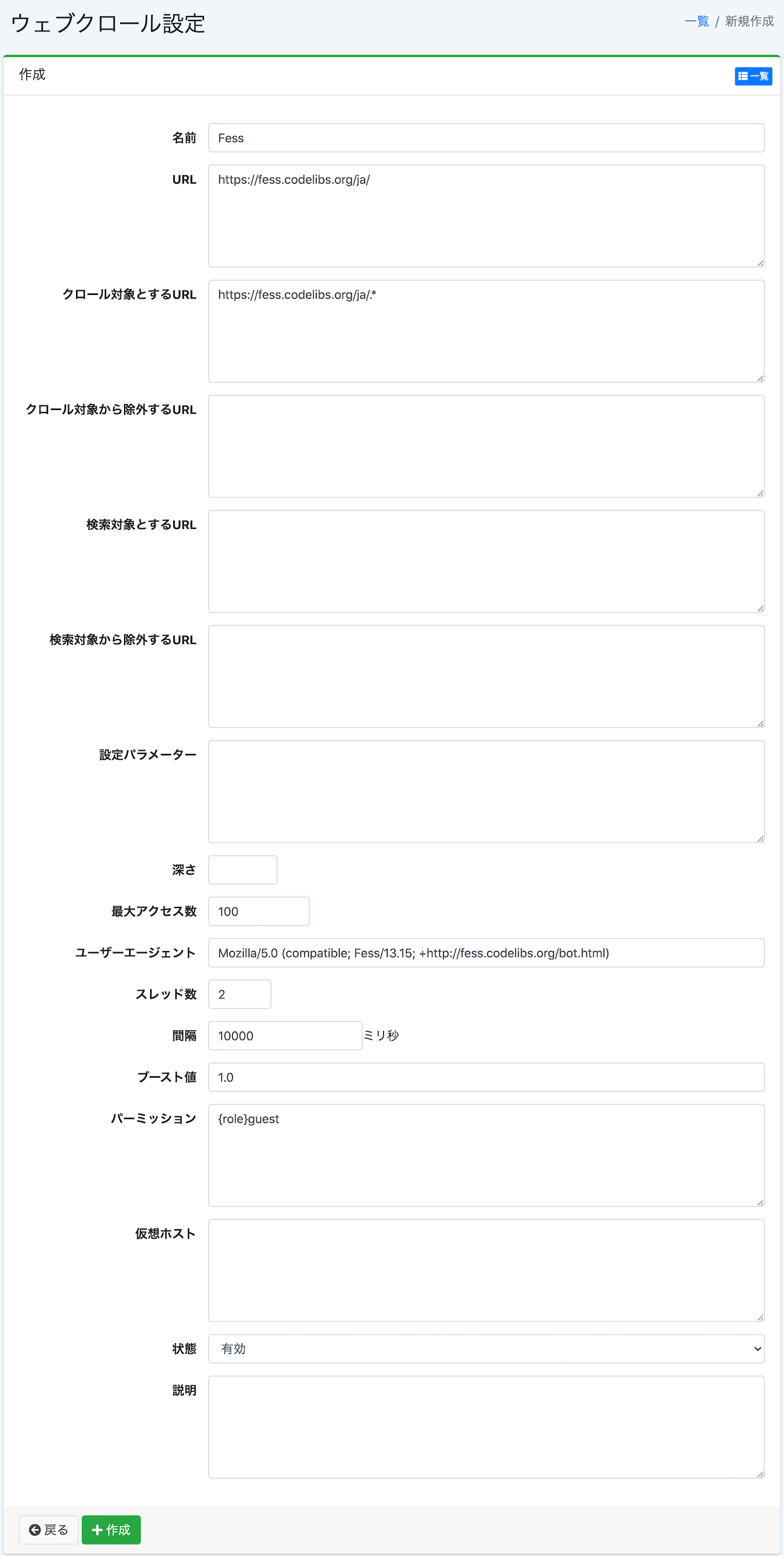
En cliquant sur [Créer], vous pouvez enregistrer la cible d’exploration. Le contenu enregistré peut être modifié en cliquant sur chaque configuration.
Enregistrement de la configuration de l’exploration web terminé 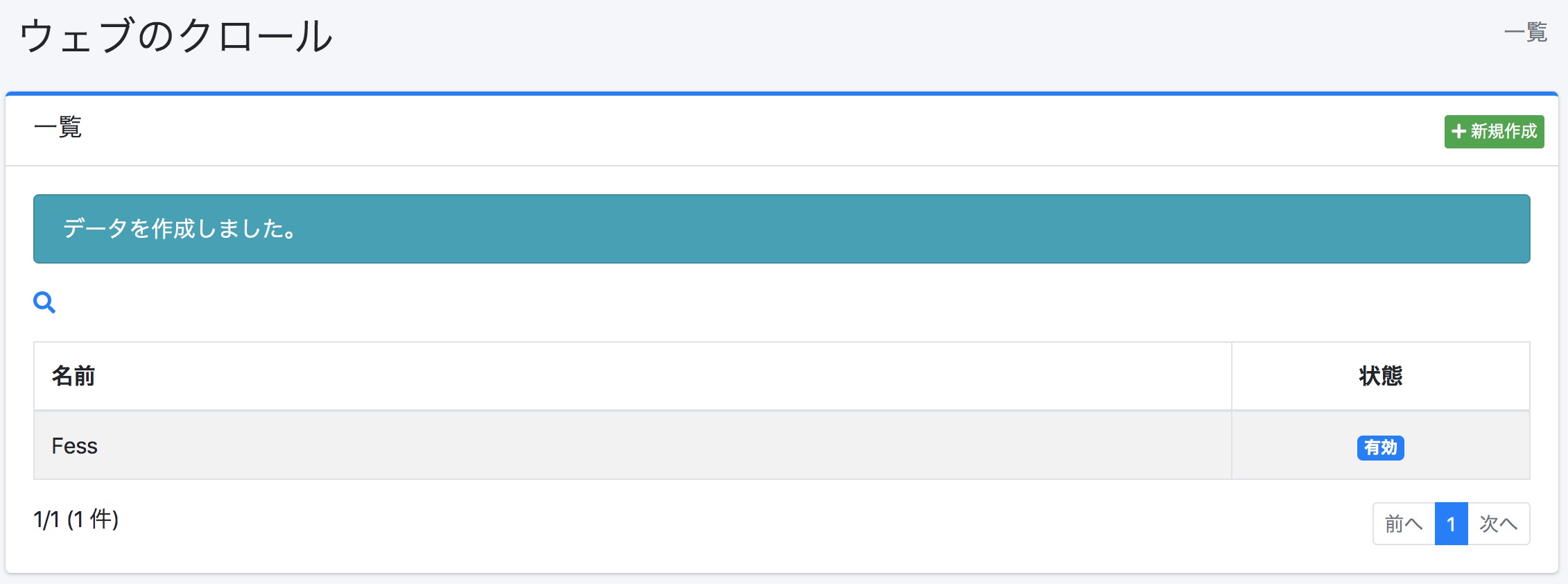
Démarrage de l’exploration
Ensuite, sélectionnez Système > Planificateur > Default Crawler et cliquez sur [Démarrer maintenant].
Sélection du planificateur 
Vous pouvez vérifier si l’exploration a démarré et si l’index est en cours de création depuis Système > Informations système > Informations d’exploration. Si l’exploration est terminée, le nombre de documents indexés s’affiche dans la taille de l’index (Web/Fichier) des [Informations d’exploration].
Vérification de l’état de l’exploration 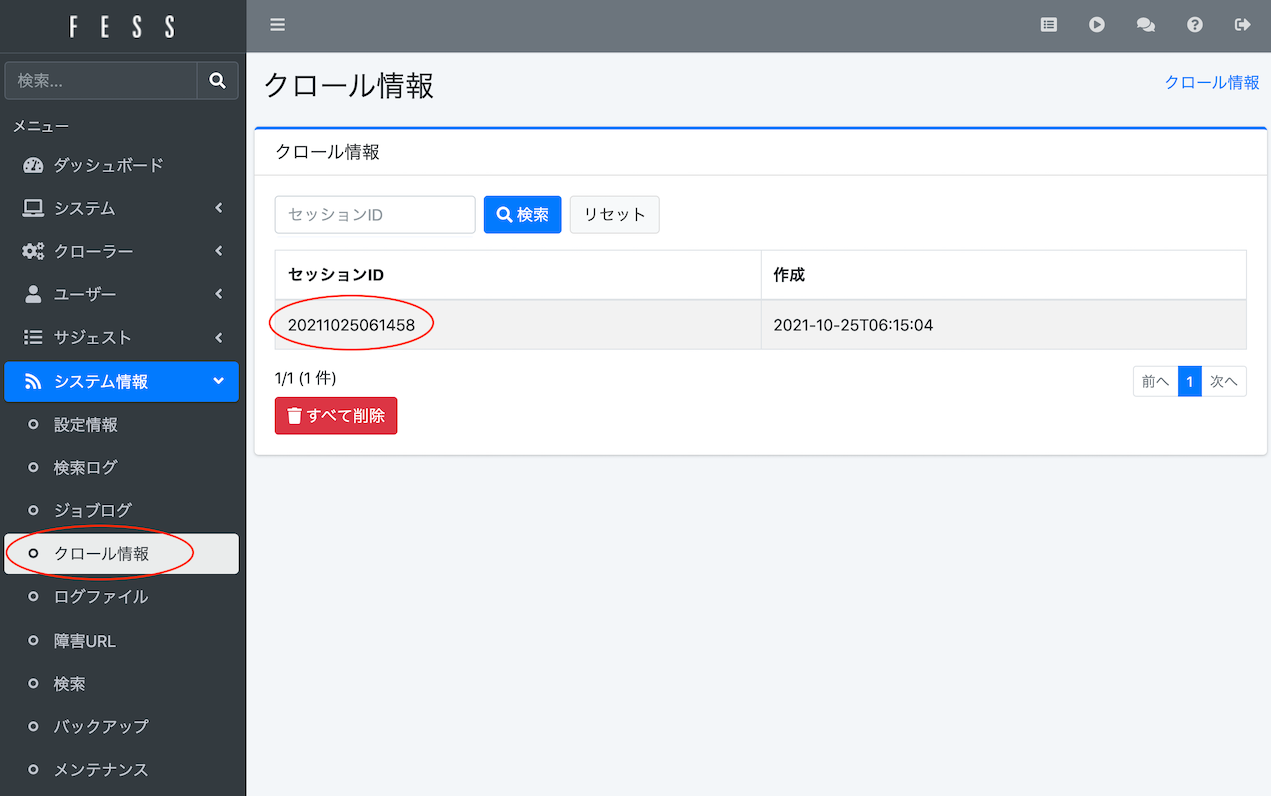
Exemple lorsque l’exploration est terminée 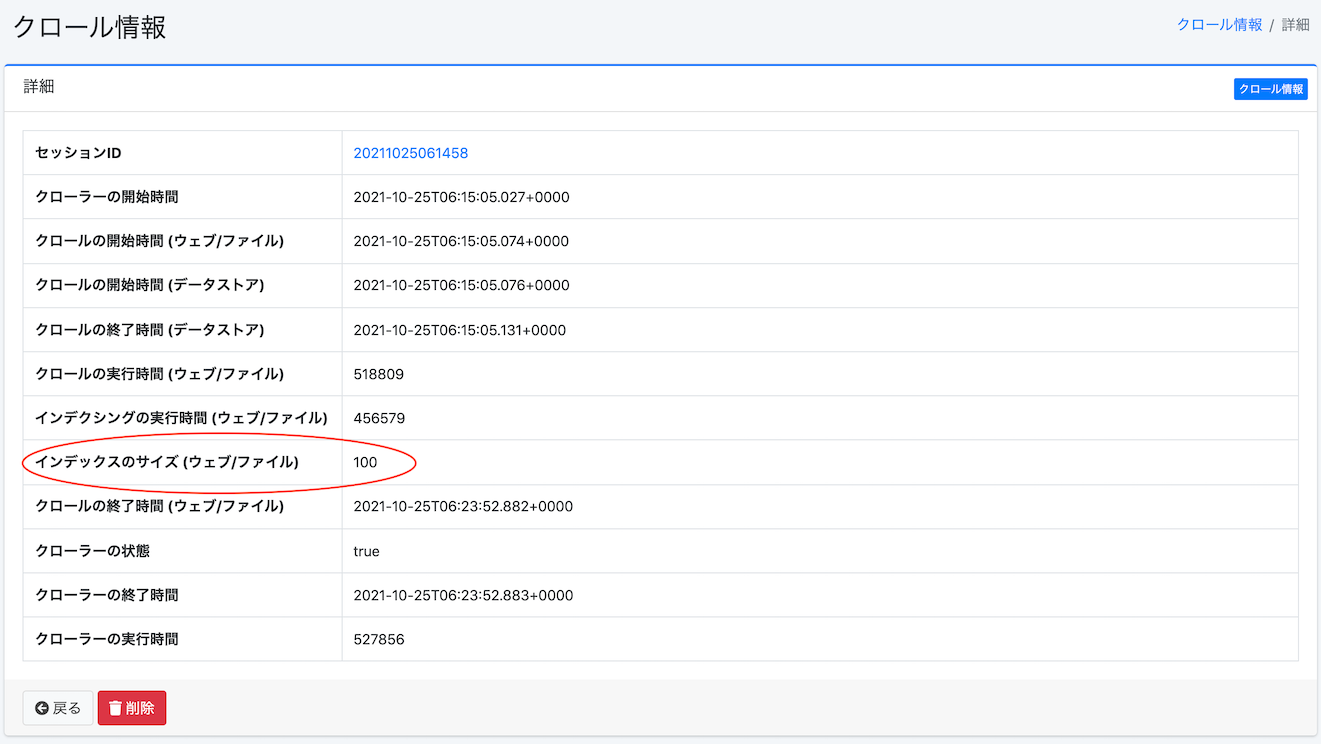
Exemple de recherche
Après la fin de l’exploration, une recherche retourne des résultats comme dans l’image ci-dessous.
Exemple de recherche 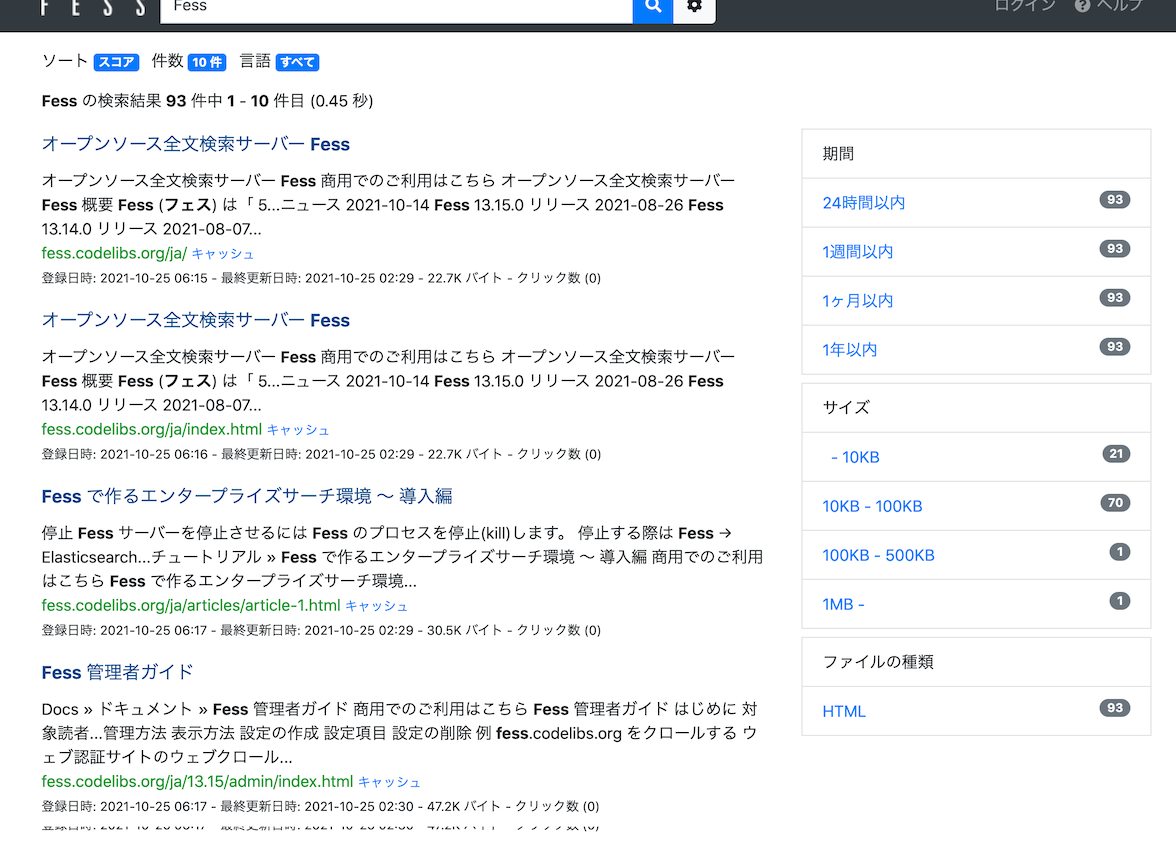
Personnalisation de l’écran de recherche
Cette section présente comment personnaliser l’écran d’accueil de recherche et l’écran de liste des résultats, qui sont les plus consultés par les utilisateurs.
Cette fois, nous allons montrer comment changer le nom du fichier de logo. Si vous souhaitez changer le design lui-même, comme il est décrit dans des fichiers JSP simples, vous pouvez le modifier si vous avez des connaissances en HTML.
Tout d’abord, l’écran d’accueil de recherche est le fichier « app/WEB-INF/view/index.jsp ».
Partie du fichier JSP de l’écran d’accueil de recherche
Pour changer l’image affichée sur l’écran d’accueil de recherche, remplacez « logo.png » ci-dessus par le nom du fichier souhaité. Placez le fichier dans « app/images ».
<la:form> et <la:message> sont des balises JSP. Par exemple, <s:form> est converti en balise form lors de l’affichage HTML réel. Pour des explications détaillées, veuillez consulter le site LastaFlute ou les sites concernant JSP.
Ensuite, la partie d’en-tête de l’écran de liste des résultats est le fichier « app/WEB-INF/view/header.jsp ».
Partie du fichier JSP d’en-tête
Pour changer l’image affichée en haut de l’écran de liste des résultats, modifiez le nom de fichier de « logo-head.png » ci-dessus. Comme pour « logo.png », placez-le dans « app/images ».
De plus, ces paramètres peuvent également être configurés depuis Système > Design de la page.
Si vous souhaitez modifier le fichier CSS utilisé dans les fichiers JSP, modifiez « style.css » placé dans « app/css ».
Conclusion
Nous avons expliqué le système de recherche en texte intégral Fess, de l’installation à la recherche, ainsi que des méthodes de personnalisation simples. Nous avons pu vous montrer qu’il est possible de construire facilement un système de recherche sans nécessiter de configuration d’environnement particulière, simplement avec un environnement d’exécution Java. Comme il peut également être introduit pour ajouter une fonctionnalité de recherche de site à un système existant, n’hésitez pas à l’essayer.