This page is generated by Machine Translation from Japanese.
The General crawl settings
Describes the settings related to crawling.
How to set up
In Administrator account click crawl General menu after login.
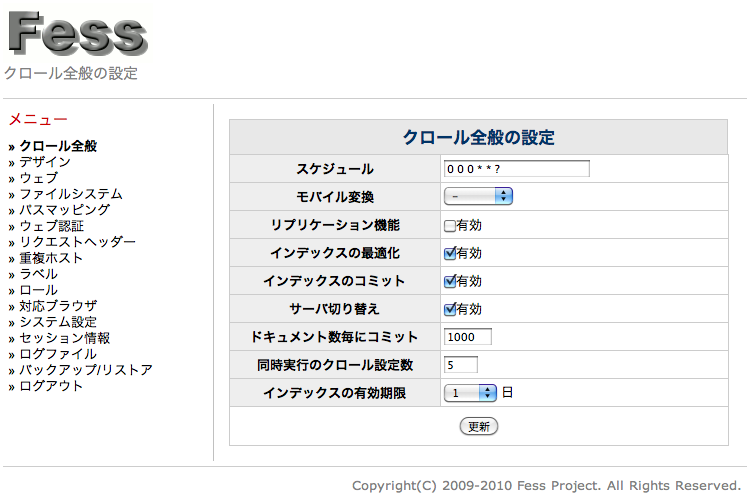
You can specify the path to a generated index and replication capabilities to enable.
Scheduled full crawl frequency
You can set the interval at which the crawl for a Web site or file system. By default, the following.
Figures are from left, seconds, minutes, during the day, month, represents a day of the week. Description format is similar to the Unix cron settings. This example, and am 0 時 0 分 to crawling daily.
Following are examples of how to write.
| 0 0 12 * *? | Each day starts at 12 pm |
| 0 15 10? * * | Day 10: 15 am start |
| 0 15 10 * *? | Day 10: 15 am start |
| 0 15 10 * *? * | Day 10: 15 am start |
| 0 15 10 * *? 2005 | Each of the 2009 start am, 10:15 |
| 0 * 14 * *? | Every day 2:00 in the PM-2: 59 pm start every 1 minute |
| 0 0 / 5 14 * *? | Every day 2:00 in the PM-2: 59 pm start every 5 minutes |
| 0 0 / 5 14, 18 * *? | Every day 2:00 pm-2: 59 pm and 6: 00 starts every 5 minutes at the PM-6: 59 pm |
| 0 0-5 14 * *? | Every day 2:00 in the PM-2: 05 pm start every 1 minute |
| 0 10, 44 14? 3 WED | Starts Wednesday March 2: 10 and 2: 44 pm |
| 0 15 10? * MON-FRI | Monday through Friday at 10:15 am start |
Also check if the seconds can be set to run at intervals 60 seconds by default. If you set seconds exactly and you should customize webapps/fess/WEB-INF/classes/chronosCustomize.dicon taskScanIntervalTime value, if enough do I see in one-hour increments.
Mobile translation
If these PC website search results on mobile devices may not display correctly. And select the mobile conversion, such as if the PC site for mobile terminals, and to show that you can. You can if you choose Google Google Wireless Transcoder allows to display content on mobile phones. For example, if site for PC and mobile devices browsing the results in the search for mobile terminals search results will link in the search result link passes the Google Wireless Transcoder. You can use smooth mobile transformation in mobile search.
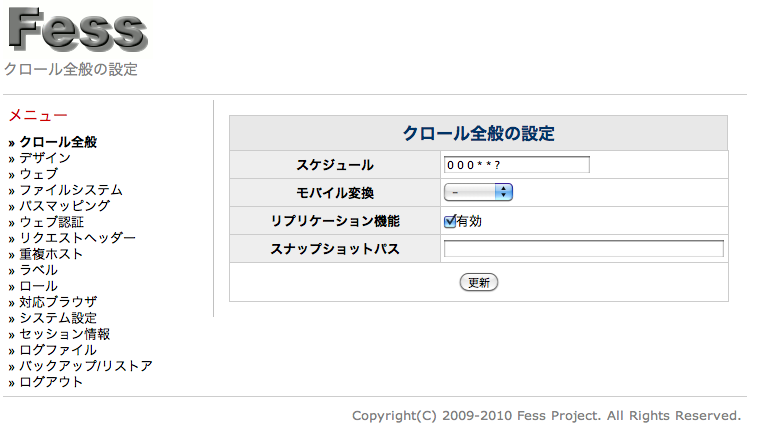
Replication features
To enable replication features that can apply already copied the Solr index generated. For example, you can use them if you want to search only in the search servers crawled and indexed on a different server, placed in front.
Index commit, optimize
After the data is registered for Solr. Index to commit or to optimize the registered data becomes available. If optimize is issued the Solr index optimization, if you have chosen, you choose to commit the commit is issued.
Server switchovers
Fess can combine multiple Solr server as a group, the group can manage multiple. Solr server group for updates and search for different groups to use. For example, if you had two groups using the Group 2 for update, search for use of Group 1. After the crawl has been completed if switching server updates for Group 1, switches to group 2 for the search. It is only valid if you have registered multiple Solr server group.
Committed to the document number of each
To raise the performance of the index in Fess while crawling and sends for Solr document in 20 units. For each value specified here because without committing to continue adding documents documents added in the Solr on performance, Solr issued document commits. By default, after you add documents 1000 is committed.
Number of concurrent crawls settings
Fess document crawling is done on Web crawling, and file system CROLL. You can crawl to a set number of values in each crawl specified here only to run simultaneously multiple. For example, crawl setting number of concurrent as 3 Web crawling set 1-set 10 if the crawling runs until the set 3 3 set 1-. Complete crawl of any of them, and will start the crawl settings 4. Similarly, setting 10 to complete one each in we will start one.
But you can specify the number of threads in the crawl settings simultaneously run crawl setting number is not indicates the number of threads to start. For example, if 3 in the number of concurrent crawls settings, number of threads for each crawl settings and 5 3 x 5 = 15 thread count up and crawling.
Expiration date of the index
You can automatically delete data after the data has been indexed. If you select the 5, with the expiration of index register at least 5 days before and had no update is removed. If you omit data content has been removed, can be used.
Snapshot path
Copy index information from the index directory as the snapshot path, if replication is enabled, will be applied.