概要
ここでは、ウェブを対象としたクロールに関する設定について説明します。
Fess で数十万件以上のドキュメントをインデックス化したい場合は、1 つのクロール設定を数万件以下にすることを推奨しています。1 つのクロール設定で数十万件を対象すると、インデックス化のパフォーマンスが低下する場合があります。
設定方法
表示方法
管理者アカウントでログイン後、メニューのウェブをクリックします。
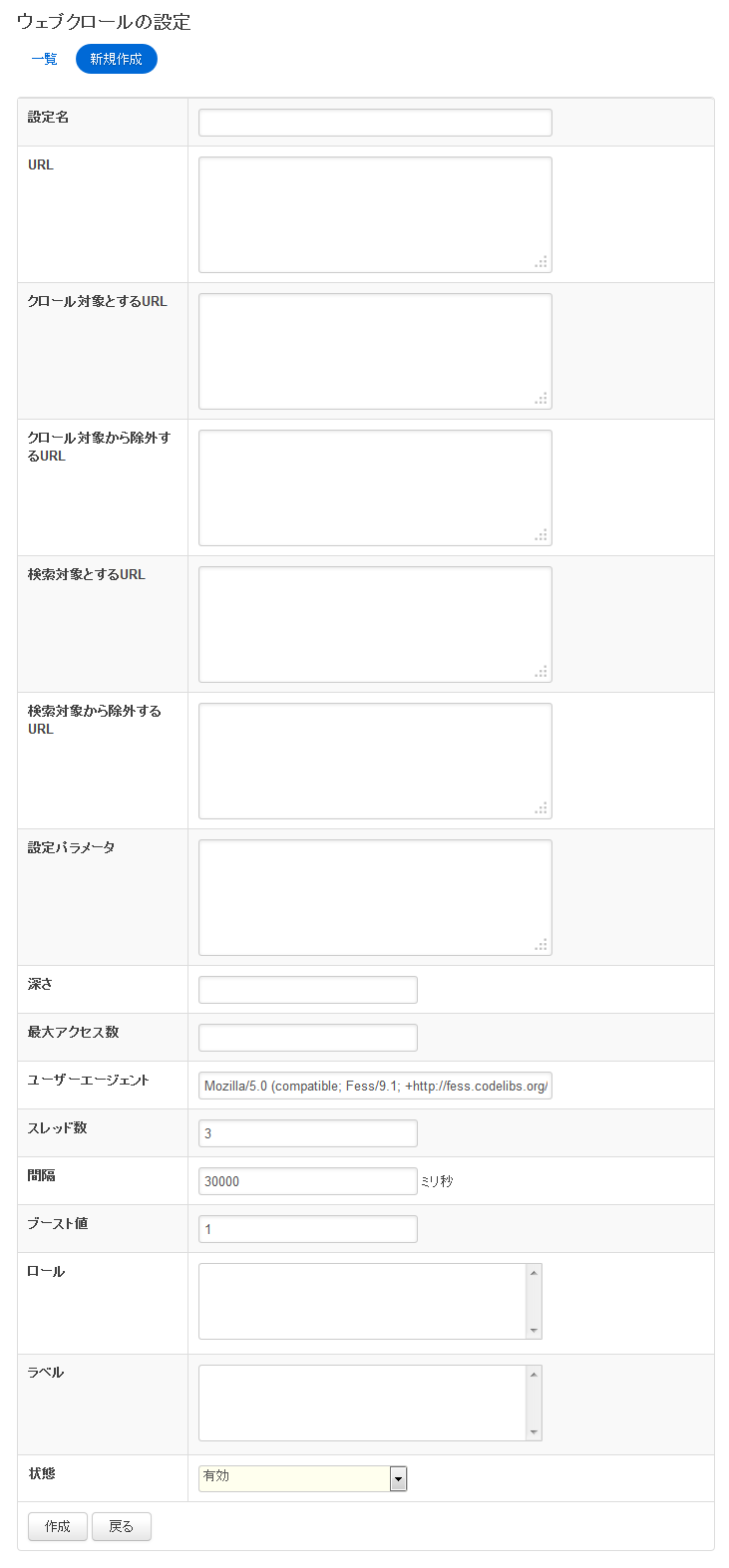
設定項目
設定名
一覧ページで表示される名前です。
URL の指定
URL は複数指定できます。http: または https: で始まるように指定します。たとえば、
のように指定します。
URL のフィルタリング
正規表現で指定することによって、特定の URL パターンをクロールや検索の対象にしたり、除外できます。
| クロール対象とする URL | 指定された正規表現の URL をクロールします。 |
| クロール対象から除外するURL | 指定された正規表現の URL をクロール対象としません。クロール対象とする URL が指定されていても、ここでの指定が優先されます。 |
| 検索対象とするURL | 指定された正規表現の URL を検索対象します。検索除外対象とする URL と指定されていても、ここでの指定が優先されます。 |
| 検索対象から除外するURL | 指定された正規表現の URL を検索対象としません。クロール対象から除外してしまうと以降の全てのリンクが検索対象とすることができませんが、クロール対象の一部だけ検索対象としない場合に指定します。 |
Table: URLフィルタリング内容一覧
たとえば、http://localhost/ 以下しかクロールしない場合は、クロール対象とする URL に
また、拡張子が png のものを対象から除外したい場合は、除外する URL に
と指定します。改行することで複数指定することが可能です。
設定パラメータ
クロールに必要な設定情報を指定することができます。
深さ
クロールしたドキュメント内に含まれるリンクを順に辿っていきますがその辿る深さを指定できます。
最大アクセス数
クロールして取得するドキュメント数を指定できます。指定しない場合は、100,000件になります。
ユーザーエージェント
クロール時に利用するユーザーエージェントを指定できます。
スレッド数
クロールするスレッド数を指定します。5 を指定した場合、5 個のスレッドで同時にウェブサイトをクロールします。
間隔
ドキュメントをクロールする間隔 (ミリ秒) です。5000 とした場合は 1 つのスレッドが 5 秒間隔でドキュメントを取得しにいきます。
スレッド数を 5 個、間隔を 1000 ミリ秒とした場合、1 秒間で 5 ドキュメントを取得しにいくことになります。ウェブサイトをクロールするときにはウェブサーバー側の負荷にもなるので、負荷をかけない十分な値を設定してください。
ブースト値
このクロール設定で検索対象とした URL に重みを付けることができます。検索結果において、他のものより上に表示したい場合に利用します。標準では 1 です。大きい値ほど優先されて、検索結果の上位に表示されます。他の結果より確実に優先して表示したい場合は、10000 などの十分に大きな値を指定します。
指定できる値は 0 以上の整数です。この値は Solr にドキュメントを追加する際のブースト値として利用されます。
ロール
利用するユーザーが特定のロールのときだけに検索結果に表示できるように制御することができます。ロールはあらかじめ設定しておく必要があります。たとえば、ポータルサーバーなどログインを必要とするシステムにおいて、利用するユーザーにより検索結果を出し分けたい場合に利用できます。
ラベル
検索結果をラベル付けすることができます。ラベルを指定すると、検索画面において、ラベルごとの検索などが可能になります。
状態
有効にすることで、設定されているクロール時刻にクロールされます。一時的にクロールしないようにしたい場合に利用できます。
その他
サイトマップ
Fess ではサイトマップファイルをクロールして、その中に定義されている URL をクロール対象とすることができます。サイトマップは http://www.sitemaps.org/ の仕様に従います。利用可能なフォーマットは XML Sitemaps、XML Sitemaps Index、テキスト (URL を改行で記述したもの) です。
サイトマップは URL に指定します。サイトマップは普通の XML ファイルやテキストであるため、クロール時にその URL が普通の XML ファイルなのかサイトマップなのかが区別できません。ですので、デフォルトでは sitemap.*.xml、sitemap.*.gz、sitemap.*txt であるファイル名の URL であればサイトマップとして処理します(webapps/fess/WEB-INF/classes/s2robot_rule.dicon でカスタマイズは可能)。
HTML ファイルをクロールするとリンクが次のクロール対象になりますが、サイトマップファイルをクロールするとその中の URL が次のクロール対象になります。