概要
Fess ではデータベースやCSVなどのデータソースをクロール対象とすることができます。 ここでは、そのために必要なデータストアの設定について説明します。
管理方法
表示方法
下図のデータストアの設定を行うための一覧ページを開くには、左メニューの [クローラ > データストア] をクリックします。
編集するには設定名をクリックします。
設定の作成
データストアの設定ページを開くには新規作成ボタンをクリックします。
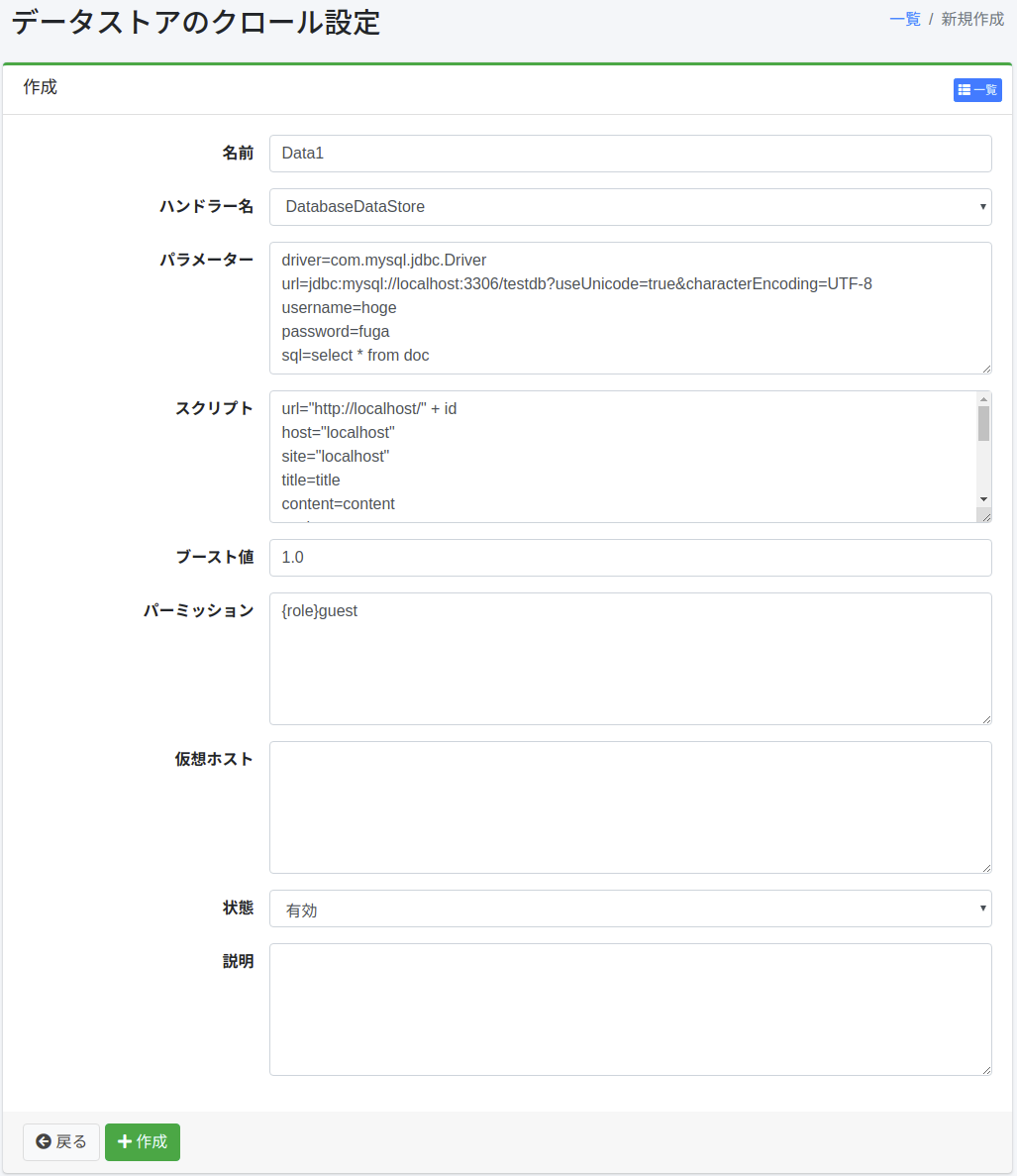
設定項目
名前
クロール設定の名前を指定します。
ハンドラ名
データストアを処理するハンドラ名です。
DatabaseDataStore: データベースをクロールする
CsvDataStore: CSV/TSVファイルを対象としてクロールする
CsvListDataStore: インデクシング対象のファイルパスを記述したCSVファイルをクロールする
EsDataStore: Elasticsearchのインデックス内のドキュメントをクロールする
EsListDataStore: インデクシング対象のファイルパスを記述したElasticsearchのインデックス内のドキュメントをクロールする
パラメータ
データストアに関するパラメータを指定します。
スクリプト
データストアから取得した値をどのフィールドに設定するかなどを指定します。 式はGroovyで記述することができます。
ブースト値
この設定でクロールしたときのドキュメントのブースト値を指定します。
パーミッション
この設定のパーミッションを指定します。 パーミッションの指定方法は、たとえば、developerグループに属するユーザーに検索結果を表示させるためには{group}developerと指定します。 ユーザー単位の指定は{user}ユーザー名、ロール単位の指定は{role}ロール名、グループ単位の指定は{group}グループ名で指定します。
ラベル
この設定のラベルを指定します。
状態
このクロール設定を利用するかどうかを指定します。
設定の削除
一覧ページの設定名をクリックし、削除ボタンをクリックすると確認画面が表示されます。 削除ボタンを押すと設定が削除されます。
例
DatabaseDataStore
データベースクロールについて説明します。
例として、以下のようなテーブルが MySQL の testdb というデータベースにあり、ユーザ名 hoge 、パスワード fuga で接続することができるとして、説明を行います。
CREATE TABLE doc (
id BIGINT NOT NULL AUTO_INCREMENT,
title VARCHAR(100) NOT NULL,
content VARCHAR(255) NOT NULL,
latitude VARCHAR(20),
longitude VARCHAR(20),
versionNo INTEGER NOT NULL,
PRIMARY KEY (id)
);
ここでは、データは以下のようなものを入れておきます.
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('タイトル 1', 'コンテンツ 1 です.', '37.77493', ' -122.419416', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('タイトル 2', 'コンテンツ 2 です.', '34.701909', '135.494977', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('タイトル 3', 'コンテンツ 3 です.', '-33.868901', '151.207091', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('タイトル 4', 'コンテンツ 4 です.', '51.500152', '-0.126236', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('タイトル 5', 'コンテンツ 5 です.', '35.681382', '139.766084', 1);
パラメータ
パラメータの設定例は以下のようになります。
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/testdb?useUnicode=true&characterEncoding=UTF-8
username=hoge
password=fuga
sql=select * from doc
パラメータは「キー=値」形式となっています。キーの説明は以下です。
| driver | ドライバクラス名 |
| url | URL |
| username | DBに接続する際のユーザ名 |
| password | DBに接続する際のパスワード |
| sql | クロール対象を得るための SQL 文 |
表: DB用設定パラメータ例
スクリプト
スクリプトの設定例は以下のようになります。
url="http://localhost/" + id
host="localhost"
site="localhost"
title=title
content=content
cache=content
digest=content
anchor=
content_length=content.length()
last_modified=new java.util.Date()
location=latitude + "," + longitude
latitude=latitude
longitude=longitude
パラメータは「キー=値」形式になっています。キーの説明は以下です。
値の側は、Groovy で記述します。 文字列はダブルクォーテーションで閉じてください。データベースのカラム名でアクセスすれば、その値になります。
| url | URL(検索結果に表示されるリンク) |
| host | ホスト名 |
| site | サイトパス |
| title | タイトル |
| content | ドキュメントのコンテンツ(インデックス対象文字列) |
| cache | ドキュメントのキャッシュ(インデックス対象ではない) |
| digest | 検索結果に表示されるダイジェスト部分 |
| anchor | ドキュメントに含まれるリンク(普通は指定する必要はありません) |
| content_length | ドキュメントの長さ |
| last_modified | ドキュメントの最終更新日 |
表: スクリプトの設定内容
ドライバ
データベースに接続する際にはドライバが必要となります。app/WEB-INF/lib に jar ファイルを置いてください。
CsvDataStore
CSVファイルを対象としたクロールについて説明します。
たとえば、/home/taro/csv ディレクトリに test.csv ファイルを以下のような内容で生成しておきます。 ファイルのエンコーディングは Shift_JIS にしておきます。
1,タイトル 1,テスト1です。
2,タイトル 2,テスト2です。
3,タイトル 3,テスト3です。
4,タイトル 4,テスト4です。
5,タイトル 5,テスト5です。
6,タイトル 6,テスト6です。
7,タイトル 7,テスト7です。
8,タイトル 8,テスト8です。
9,タイトル 9,テスト9です。
パラメータ
パラメータの設定例は以下のようになります。
directories=/home/taro/csv
fileEncoding=Shift_JIS
パラメータは「キー=値」形式となっています。キーの説明は以下です。
| directories | CSVファイルが含まれるディレクトリ (.csvまたは.tsv) |
| files | CSVファイル (直接指定する場合) |
| fileEncoding | CSVファイルのエンコーディング |
| separatorCharacter | 区切り文字 |
表: CSVファイル用設定パラメータ例
スクリプト
スクリプトの設定例は以下のようになります。
url="http://localhost/" + cell1
host="localhost"
site="localhost"
title=cell2
content=cell3
cache=cell3
digest=cell3
anchor=
content_length=cell3.length()
last_modified=new java.util.Date()
パラメータは「キー=値」形式になります。 キーはデータベースクロールの場合と同様です。 CSVファイル内のデータは、cell[数字]で保持しています(数字は 1 から始まります)。 CSVファイルのセルにデータが存在しない場合はnullになる場合があります。
EsDataStore
データの取得先がelasticsearchになりますが、基本的な利用方法はCsvDataStoreと同様です。
パラメータ
パラメータの設定例は以下のようになります。
settings.cluster.name=elasticsearch
hosts=localhost:9300
index=logindex
type=data
パラメータは「キー=値」形式となっています。キーの説明は以下です。
| settings.* | elasticsearchのSettings情報 |
| hosts | 接続先のelasticsearch |
| index | インデックス名 |
| type | タイプ名 |
| query | 取得する条件のクエリー |
表: elasticsearch用設定パラメータ例
スクリプト
スクリプトの設定例は以下のようになります。
url=source.url
host="localhost"
site="localhost"
title=source.title
content=source.content
digest=
anchor=
content_length=source.size
last_modified=new java.util.Date()
パラメータは「キー=値」形式になります。 キーはデータベースクロールの場合と同様です。 source.*により値を取得して、設定することができます。