The General crawl settings
This page is generated by Machine Translation from Japanese.
Overview
Describes the settings related to crawling.
How to set up
How to display
In Administrator account click crawl General menu after login.
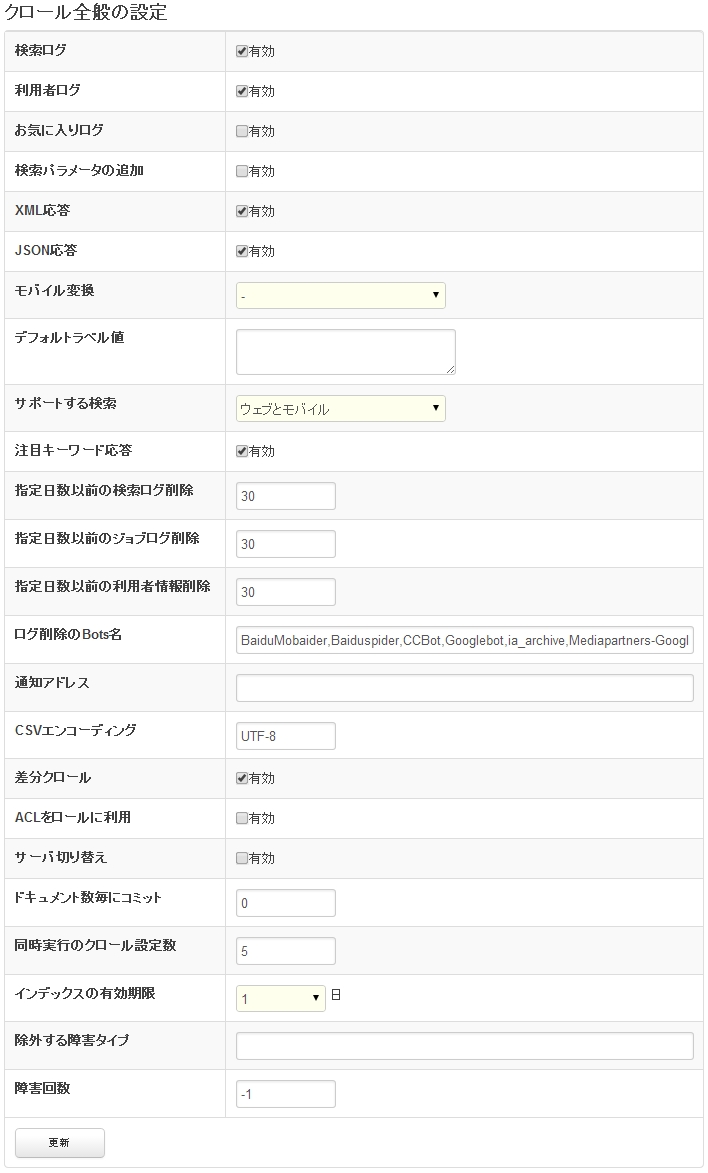
Setting item
Search log
When the user enters a search, the search the output log. If you want to get search statistics to enable.
User log
Save the information you find. Identifying the users becomes possible.
Favorite log
You can collect the search result was judged good by the user. Search result voting link appears to result in list screen, so that link press made the record. You can also reflect the results collected during the crawl index.
Add search parameters
Search results link attaches to the search term. To display the find search terms in PDF becomes possible.
XML response
Search results can be retrieved in XML format. http://localhost:8080/ Fess /XML? can get access query = search term.
JSON response
Search results available in JSON format. http://localhost:8080/ Fess /JSON? can get access query = search term.
Mobile translation
If these PC website search results on mobile devices may not display correctly. And select the mobile conversion, such as if the PC site for mobile terminals, and to show that you can. You can if you choose Google Google Wireless Transcoder allows to display content on mobile phones. For example, if site for PC and mobile devices browsing the results in the search for mobile terminals search results will link in the search result link passes the Google Wireless Transcoder. You can use smooth mobile transformation in mobile search.
The default label value
You can specify the label to see if the label by default,. Specifies the value of the label.
Search support
You can specify whether or not to display a search screen. If you select Web unusable for mobile search screen. If not available not available search screen. And if you want to create a dedicated index server and select not available.
Featured keyword response
In JSON format often find search words becomes available. http://localhost:8080/ Fess /JSON? can be retrieved by accessing the type = hotsearchword.
Specify the number of days before search log delete
Delete a search log for the specified number of days ago. One day in the one log purge old log is deleted.
Specify the number of days before job log delete
Delete the job days before the specified date. One day in the one log purge old log is deleted.
Specify the number of days before user information removed
Delete the user information for the specified number of days ago. One day in the one log purge old log is deleted.
Log deletion Bots name
Specifies the Bots name Bots you want to remove from the search log logs included in the user agent by commas (,). Log is deleted by log purge once a day.
Notification address
Specifies the email address to send information about crawl upon completion crawl.
CSV encoding
Specifies the encoding for the CSV will be available in the backup and restore.
Incremental crawling
Crawl as been updated to enable incremental crawl compared lastModified field value and the target document’s modification date (if the HTTP’s timestamp if LAST_MODIFIED values, file).
ACL by using roles
File additional group access rights information added to the role.
Server switchovers
Fess can combine multiple Solr server as a group, the group can manage multiple. Solr server group for updates and search for different groups to use. For example, if you had two groups using the Group 2 for update, search for use of Group 1. After the crawl has been completed if switching server updates for Group 1, switches to group 2 for the search. It is only valid if you have registered multiple Solr server group.
Committed to the document number of each
In Fess in 10 units send the document for Solr. For each value specified here Solr issued document commits. If 0 commit is performed after crawl completion.
Number of concurrent crawls settings
Fess document crawling is done on Web crawling, and file system CROLL. You can crawl to a set number of values in each crawl specified here only to run simultaneously multiple. For example, crawl setting number of concurrent as 3 Web crawling set 1-set 10 if the crawling runs until the set 3 3 set 1-. Complete crawl of any of them, and will start the crawl settings 4. Similarly, setting 10 to complete one each in we will start one.
But you can specify the number of threads in the crawl settings simultaneously run crawl setting number is not indicates the number of threads to start. For example, if 3 in the number of concurrent crawls settings, number of threads for each crawl settings and 5 3 x 5 = 15 thread count up and crawling.
Expiration date of the index
You can automatically delete data after the data has been indexed. If you select the 5, with the expiration of index register at least 5 days before and had no update is removed. If you omit data content has been removed, can be used.
Disability types to exclude
Registered disabled URL URL exceeds the failure count next time you crawl to crawl out. Does not need to monitor the fault type is being crawled next time by specifying this value.
Failure count
Disaster URL exceeds the number of failures will crawl out.