Data Store Configuration
Overview
Data Store Crawling Configuaration page manages configurations for crawling on Data Store, such as Database.
Management Operations
Display Configurations
Select Crawler > Data Store in the left menu to display a list page of Data Store Configuration, as below.
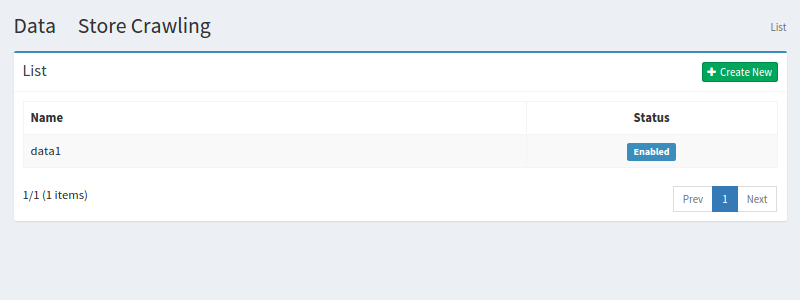
Click a configuration name if you want to edit it.
Create Configuration
Click Create New button to display a form page for Data Store configuration.
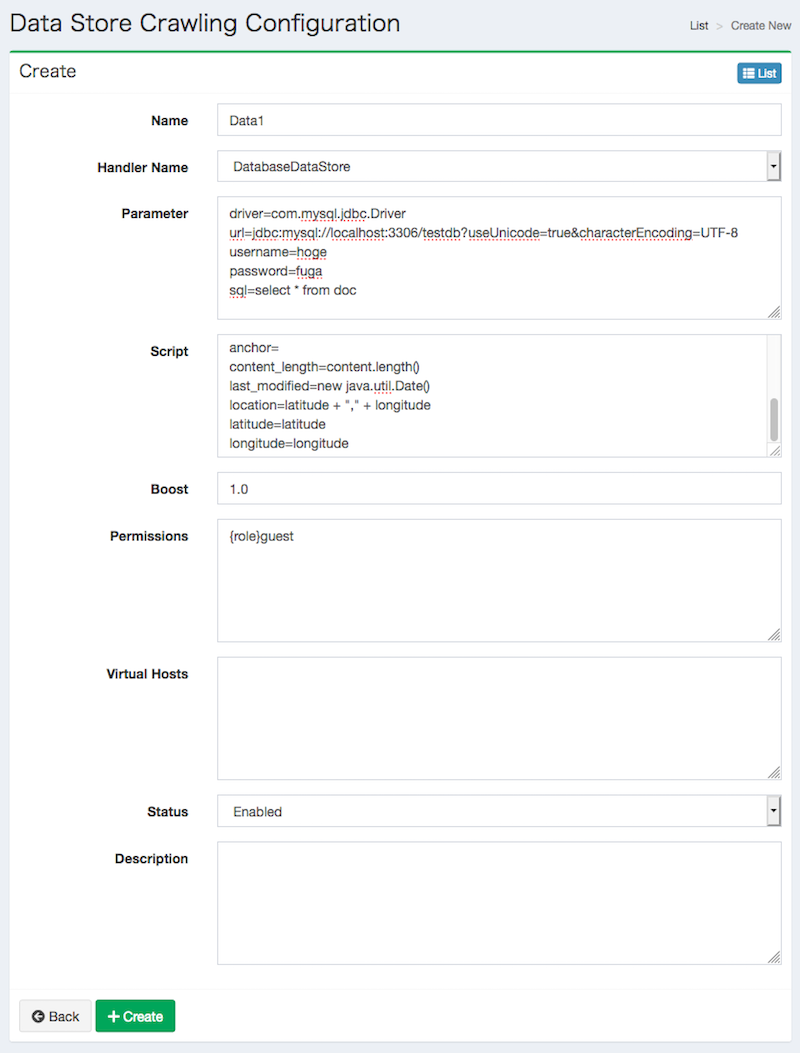
Configurations
Name
Configuration name.
Handler Name
Type of Data Store.
DatabaseDataStore: crawl data in Database.
CsvDataStore: crawl data in CSV file.
CsvListDataStore: crawl file paths in CSV file.
EsDataStore: crawl documents in an index of elasticsearch.
EsListDataStore: crawl file paths in an index of elasticsearch.
GitBucketDataStore: crawl repositories of GitBucket. (See gitbucket-fess-plugin for more detail.)
Parameter
Parameters for Data Store crawling.
Script
Field mapping on index. The format is key/value, such as [Field Name In Index]=[Value(Groovy Supported)].
Boost
Boost value is a weight for indexed documents of this configuration.
Permissions
Permissions for this configuration. This format is “{user/group/role}name”. For example, to display search results on users who belong to developer group, the permission is {group}developer.
Virtual Hosts
Virtual Host keys for this configuration. e.g. fess (if setting Host:fess.codelibs.org=fess in General)
Status
If enabled, the scheduled job of Default Crawler includes this configuration.
Description
Comments for this configuration.
Delete Configuration
Click a configuration on a list page, and click Delete button to display a confirmation dialog. Click Delete button to delete the configuration.
Example
DatabaseDataStore
This section describes Database crawling.
This example uses MySQL. There is the following table in testdb, and you can access data with username=foo and password=bar.
CREATE TABLE doc (
id BIGINT NOT NULL AUTO_INCREMENT,
title VARCHAR(100) NOT NULL,
content VARCHAR(255) NOT NULL,
latitude VARCHAR(20),
longitude VARCHAR(20),
versionNo INTEGER NOT NULL,
PRIMARY KEY (id)
);
Insert the following data.
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('Title 1', 'This is Content 1.', '37.77493', ' -122.419416', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('Title 2', 'This is Content 2.', '34.701909', '135.494977', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('Title 3', 'This is Content 3.', '-33.868901', '151.207091', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('Title 4', 'This is Content 4.', '51.500152', '-0.13.036', 1);
INSERT INTO doc (title, content, latitude, longitude, versionNo) VALUES ('Title 5', 'This is Content 5.', '35.681382', '139.766084', 1);
Parameter
Set parameters of crawling config as below.
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/testdb?useUnicode=true&characterEncoding=UTF-8
username=foo
password=bar
sql=select * from doc
The value of parameters is key/value format. The description is below.
| driver | JDBC driver class |
| url | URL |
| username | Username to access to DB |
| password | Password to access to DB |
| sql | SQL statement to crawl data |
Table: Parameter example for DB
Script
Set script values of crawling config as below.
url="http://localhost/" + id
host="localhost"
site="localhost"
title=title
content=content
digest=content
anchor=
content_length=content.length()
last_modified=new java.util.Date()
location=latitude + "," + longitude
latitude=latitude
longitude=longitude
The format is key/value. For specified values, Groovy language is available. The description for Script is below.
| url | URL(Displayed link in search result page) |
| host | Host name |
| site | Site path |
| title | Title |
| content | Content |
| cache | Content Cache(Not search target) |
| digest | Displayed description in search result page |
| anchor | Links contained in this document(optional) |
| content_length | Content length |
| last_modified | Last modified for this document |
Table: Configuaration for Script
JDBC Driver
To crawl data in database, JDBC driver is needed. Put jar file into app/WEB-INF/lib directory. In this example, copy mysql-connector-java-5.1.39.jar to app/WEB-INF/lib.
CsvDataStore
CsvDataStore is CSV file crawling.
For example, create test.csv in /home/john/csv and the content is below.
1,Title 1,This is Test1.
2,Title 2,This is Test2.
3,Title 3,This is Test3.
4,Title 4,This is Test4.
5,Title 5,This is Test5.
6,Title 6,This is Test6.
7,Title 7,This is Test7.
8,Title 8,This is Test8.
9,Title 9,This is Test9.
Parameter
Set parameters of crawling config as below.
directories=/home/john/csv
fileEncoding=UTF-8
The value of parameters is key/value format. The description is below.
| directories | Directories which contains csv file(.csv or .tsv) |
| files | CSV files (if you want to specify them) |
| fileEncoding | Encofing of CSV files |
| separatorCharacter | Separator character in CSV content |
Table: Parameter example for CSV file
Script
Set script values of crawling config as below.
url="http://localhost/" + cell1
host="localhost"
site="localhost"
title=cell2
content=cell3
cache=cell3
digest=cell3
anchor=
content_length=cell3.length()
last_modified=new java.util.Date()
The format is key/value. For keys, they are the same as database crawling. You can use values in CSV file as cell[number](cell1 is a first cell). If cell does not exist, it returns null.